

Visions of Chaos is a professional high end software application for Windows. It is simple enough for people who do not understand the mathematics behind it, but advanced enough for enthusiasts to tweak and customise to their needs. It is the most complete all in one application dealing with Chaos Theory and Machine Learning available. Every mode is written to give the best possible quality output. There are thousands of sample files included to give you an idea of what Visions of Chaos is capable of.
For informational purposes only
This is a fluid document, compiled from different notes/docs, originally started in ~2008, having grown slowly from my more general manifesto of that period and frequently been revised to help steer my own practice (the artistic parts) ever since.
All of the things listed here are "soft" guidelines & considerations, not an exhaustive set of hard rules! Various omissions and exceptions do exist, and the latter are explicitly encouraged! Yet, I do not imagine there'll be even minor agreement about these highly subjective, personal stances — in fact I'm very much expecting the opposite... So I'm also not publishing these bullet points to start any form of debate, but, after all these years, it's important for me to openly document how I myself have been approaching generative art projects, the topics & goals I've been trying to research & learn about, also including some of the hard lessons learned, in the hope some of these considerations might be useful for others too.
Since that list already has become rather long, there're also a bunch of other considerations & clarifications I've had to omit for now. Please keep that in mind when reading, and if some sections are maybe a little too brief/unclear...
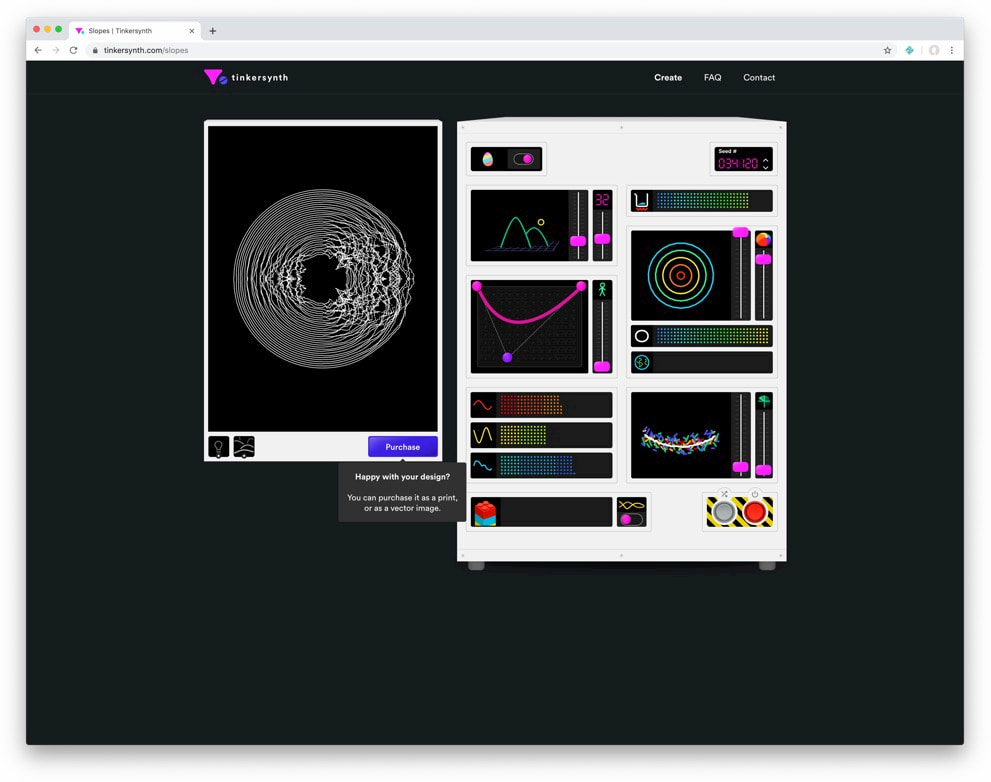
Tinkersynth is an experimental art project. It lets you create unique generative art
by making serendipitous discoveries through experimentation.
More concretely, Tinkersynth is a design tool where you build art by poking at sliders and buttons. The goal isn't to provide a linear path to a specific piece of art, but rather to encourage experimentation. Tinkersynth prioritizes being delighted by unexpected effects rather than creating an intuitive, predictable tool.
In a former life, Tinkersynth was also a store which sold the rights to digital products, as well as physical fine-art prints.
Tinkersynth was created by me, Josh Comeau.
Have you ever wanted to ...
– export 10,000 mass-customized copies of your InDesign document?
– use spatial-tiling algorithms to create your layouts?
– pass real-time data from any source directly into your InDesign project?
– create color palettes based on algorithms?
– or simply reconsider what print can be?
basil.js is ...
– making scripting in InDesign available to designers and artists.
– in the spirit of Processing and easy to learn.
– based on JavaScript and extends the existing API of InDesign.
– a project by The Basel School of Design in Switzerland.
– has been released as open source in February 2013!

Neural Cellular Automata (NCA We use NCA to refer to both Neural Cellular Automata and Neural Cellular Automaton.) are capable of learning a diverse set of behaviours: from generating stable, regenerating, static images , to segmenting images , to learning to “self-classify” shapes . The inductive bias imposed by using cellular automata is powerful. A system of individual agents running the same learned local rule can solve surprisingly complex tasks. Moreover, individual agents, or cells, can learn to coordinate their behavior even when separated by large distances. By construction, they solve these tasks in a massively parallel and inherently degenerate Degenerate in this case refers to the biological concept of degeneracy. way. Each cell must be able to take on the role of any other cell - as a result they tend to generalize well to unseen situations.
In this work, we apply NCA to the task of texture synthesis. This task involves reproducing the general appearance of a texture template, as opposed to making pixel-perfect copies. We are going to focus on texture losses that allow for a degree of ambiguity. After training NCA models to reproduce textures, we subsequently investigate their learned behaviors and observe a few surprising effects. Starting from these investigations, we make the case that the cells learn distributed, local, algorithms.
To do this, we apply an old trick: we employ neural cellular automata as a differentiable image parameterization .
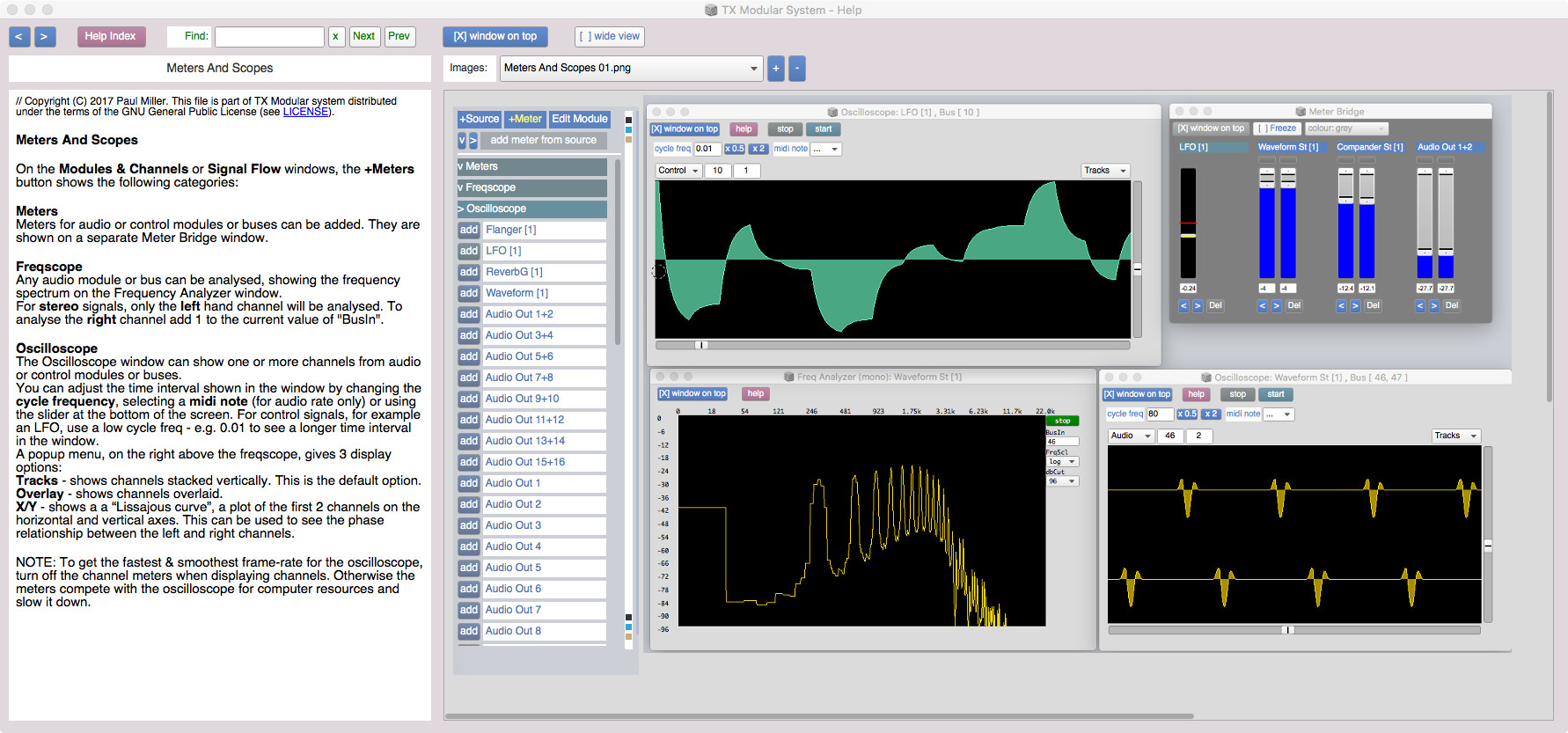
The TX Modular System is open source audio-visual software for modular synthesis and video generation, built with SuperCollider (https://supercollider.github.io) and openFrameworks (https://openFrameworks.cc).
It can be used to build interactive audio-visual systems such as: digital musical instruments, interactive generative compositions with real-time visuals, sound design tools, & live audio-visual processing tools.
This version has been tested on MacOS (0.10.11) and Windows (10). The audio engine should also work on Linux.
The visual engine, TXV, has only been built so far for MacOS and Windows - it is untested on Linux.
The current TXV MacOS build will only work with Mojave (10.14) or earlier (10.11, 10.12 & 10.13) - but NOT Catalina (10.15) or later.
You don't need to know how to program to use this system. But if you can program in SuperCollider, some modules allow you to edit the SuperCollider code inside - to generate or process audio, add modulation, create animations, or run SuperCollider Patterns.
Audio stream : http://icecast.spc.org:8000/longplayer
Longplayer is a one thousand year long musical composition. It began playing at midnight on the 31st of December 1999, and will continue to play without repetition until the last moment of 2999, at which point it will complete its cycle and begin again. Conceived and composed by Jem Finer, it was originally produced as an Artangel commission, and is now in the care of the Longplayer Trust.
How does Longplayer work?
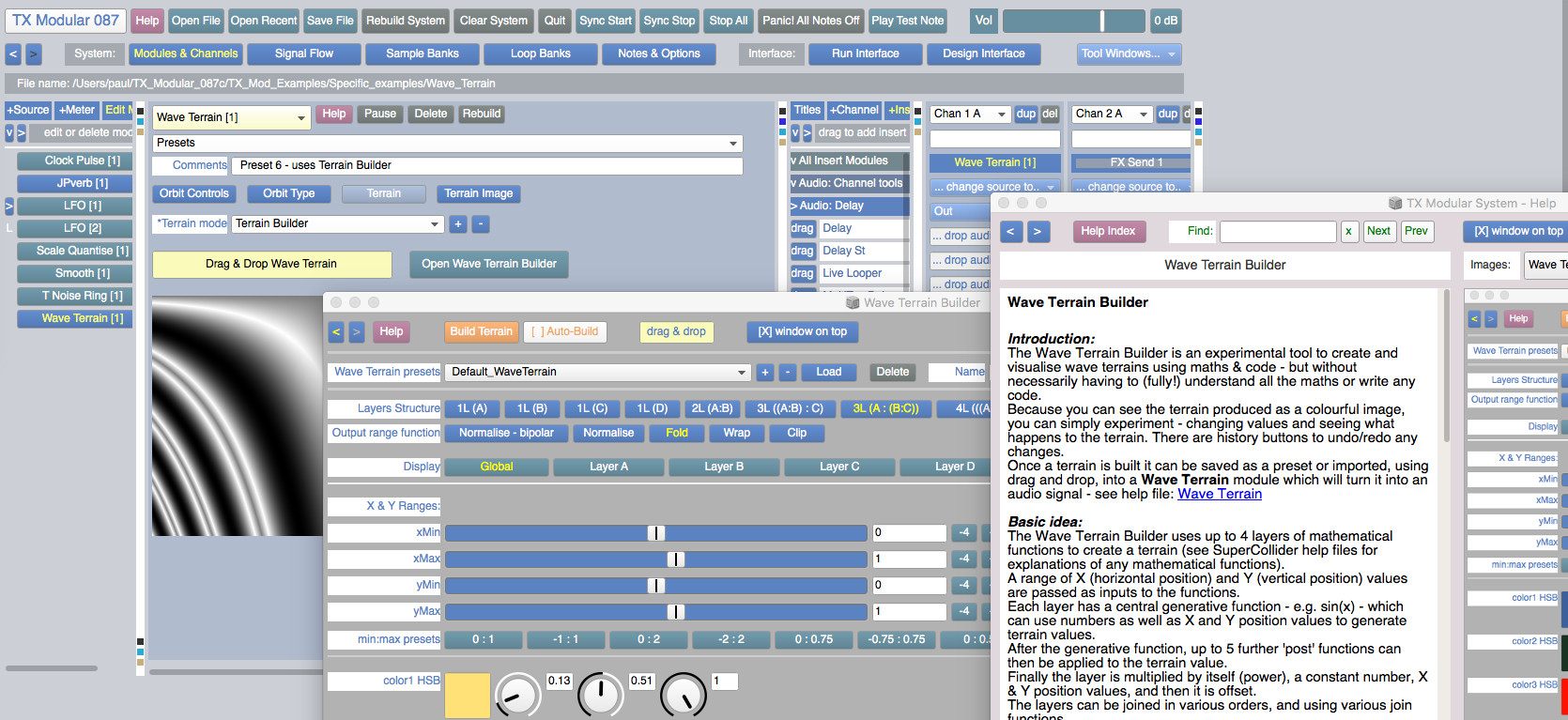
Early calculations made while trying to establish the correct increments. At the bottom is an estimation of the playing positions on the 7th of January 2000 based on these values.
The composition of Longplayer results from the application of simple and precise rules to six short pieces of music. Six sections from these pieces – one from each – are playing simultaneously at all times. Longplayer chooses and combines these sections in such a way that no combination is repeated until exactly one thousand years has passed. At this point the composition arrives back at the point at which it first started. In effect Longplayer is an infinite piece of music repeating every thousand years – a millennial loop.
The six short pieces of music are transpositions of a 20’20” score for Tibetan Singing Bowls, the ‘source music’.[1] These transpositions vary from the original not only in pitch but also, proportionally, in duration.[2]
Every two minutes a starting point in each of the six pieces is calculated, from which they then play for the next two minutes. Each starting point is calculated by adding a specific length of time to its previous starting point.[3] For each of the six pieces of music this length of time is unique and unvarying. The relationships between these six precisely calculated increments are what gives Longplayer its exact one thousand year long duration.
Rates of Change
In the diagram below, the six simultaneous transpositions are represented by the six circles, whose circumference represents the length of the transposed source music. The solid rectangles represent the two minute sections presently playing. The unique increments by which these six sections advance determine their respective rates of change. These reflect different flows of time, from a glacial crawl to the almost perceptible sweep of an hour hand. The incremental advance of the third circle, is so small that it will take the full thousand years for it to pass once through the source music. Conversely the increment for the second circle is such that it makes its way through the music every 3.7 days. The diagram updates every 2 minutes
https://eclipticalis.com/
http://teropa.info/loop
https://daily.bandcamp.com/lists/generative-music-guide
https://github.com/npisanti/ofxPDSP
Systems music is an idea that explores the following question: What if we could, instead of making music, design systems that generate music for us?
This idea has animated artists and composers for a long time and emerges in new forms whenever new technologies are adopted in music-making.
In the 1960s and 70s there was a particularly fruitful period. People like Steve Reich, Terry Riley, Pauline Oliveros, and Brian Eno designed systems that resulted in many landmark works of minimal and ambient music. They worked with the cutting edge technologies of the time: Magnetic tape recorders, loops, and delays.
Today our technological opportunities for making systems music are broader than ever. Thanks to computers and software, they're virtually endless. But to me, there is one platform that's particularly exciting from this perspective: Web Audio. Here we have a technology that combines audio synthesis and processing capabilities with a general purpose programming language: JavaScript. It is a platform that's available everywhere — or at least we're getting there. If we make a musical system for Web Audio, any computer or smartphone in the world can run it.
With Web Audio we can do something Reich, Riley, Oliveros, and Eno could not do all those decades ago: They could only share some of the output of their systems by recording them. We can share the system itself. Thanks to the unique power of the web platform, all we need to do is send a URL.
In this guide we'll explore some of the history of systems music and the possibilities of making musical systems with Web Audio and JavaScript. We'll pay homage to three seminal systems pieces by examining and attempting to recreate them: "It's Gonna Rain" by Steve Reich, "Discreet Music" by Brian Eno, and "Ambient 1: Music for Airports", also by Brian Eno.
Table of Contents
"Is This for Me?"
How to Read This Guide
The Tools You'll Need
Steve Reich - It's Gonna Rain (1965)
Setting Up itsgonnarain.js
Loading A Sound File
Playing The Sound
Looping The Sound
How Phase Music Works
Setting up The Second Loop
Adding Stereo Panning
Putting It Together: Adding Phase Shifting
Exploring Variations on It's Gonna Rain
Brian Eno - Ambient 1: Music for Airports, 2/1 (1978)
The Notes and Intervals in Music for Airports
Setting up musicforairports.js
Obtaining Samples to Play
Building a Simple Sampler
A System of Loops
Playing Extended Loops
Adding Reverb
Putting It Together: Launching the Loops
Exploring Variations on Music for Airports
Brian Eno - Discreet Music (1975)
Setting up discreetmusic.js
Synthesizing the Sound Inputs
Setting up a Monophonic Synth with a Sawtooth Wave
Filtering the Wave
Tweaking the Amplitude Envelope
Bringing in a Second Oscillator
Emulating Tape Wow with Vibrato
Understanding Timing in Tone.js
Transport Time
Musical Timing
Sequencing the Synth Loops
Adding Echo
Adding Tape Delay with Frippertronics
Controlling Timbre with a Graphic Equalizer
Setting up the Equalizer Filters
Building the Equalizer Control UI
Going Forward
Demonstration tutorial of retraining OpenAI’s GPT-2-small (a text-generating Transformer neural network) on a large public domain Project Gutenberg poetry corpus to generate high-quality English verse.
https://jalammar.github.io/illustrated-gpt2/
Other tutorial : https://medium.com/@ngwaifoong92/beginners-guide-to-retrain-gpt-2-117m-to-generate-custom-text-content-8bb5363d8b7f
https://github.com/minimaxir/gpt-2-simple
Example : http://textsynth.org/
Datasets :
https://www.kaggle.com/datasets
https://github.com/awesomedata/awesome-public-datasets
Scrap webpage with python :
https://www.crummy.com/software/BeautifulSoup/
https://github.com/EugenHotaj/beatles/blob/master/scraper.py
https://github.com/shawwn/colab-tricks
Built by Adam King (@AdamDanielKing) as an easier way to play with OpenAI's new machine learning model. In February, OpenAI unveiled a language model called GPT-2 that generates coherent paragraphs of text one word at a time.
AI research that touches on dialogue and story generation. As before, I’m picking a few points of interest, summarizing highlights, and then linking through to the detailed research.
This one is about a couple of areas of natural language processing and generation, as well as sentiment understanding, relevant to how we might realize stories and dialogue with particular surface features and characteristics.



https://ganbreeder.app/i?k=1f98015a7ce950101ec1c5ee
Ganbreeder is a collaborative art tool for discovering images. Images are 'bred' by having children, mixing with other images and being shared via their URL. This is an experiment in using breeding + sharing as methods of exploring high complexity spaces. GAN's are simply the engine enabling this. Ganbreeder is very similar to, and named after, Picbreeder. It is also inspired by an earlier project of mine Facebook Graffiti which demonstrated the creative capacity of crowds. Ganbreeder uses these BigGAN models and the source code is available.
We call them "seeds". Each seed is a machine learning example you can start playing with. Explore, learn and grow them into whatever you like.



It's all a game of construction — some with a brush, some with a shovel, some choose a pen.
Jackson Pollock

…and some, including myself, choose neural networks. I’m an artist, and I've also been building commercial software for a long while. But art and software used to be two parallel tracks in my life; save for the occasional foray into generative art with Processing and computational photography, all my art was analog… until I discovered GANs (Generative Adversarial Networks).
Since the invention of GANs in 2014, the machine learning community has produced a number of deep, technical pieces about the technique (such as this one). This is not one of those pieces. Instead, I want to share in broad strokes some reasons why GANs are excellent artistic tools and the methods I have developed for creating my GAN-augmented art.
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/
https://github.com/eriklindernoren/PyTorch-GAN
https://heartbeat.fritz.ai/introduction-to-generative-adversarial-networks-gans-35ef44f21193
https://github.com/nightrome/really-awesome-gan
https://github.com/zhangqianhui/AdversarialNetsPapers
https://github.com/io99/Resources
https://github.com/yunjey/pytorch-tutorial
https://github.com/bharathgs/Awesome-pytorch-list
https://old.reddit.com/r/MachineLearning
http://www.codingwoman.com/generative-adversarial-networks-entertaining-intro/
https://medium.com/@jonathan_hui/gan-gan-series-2d279f906e7b
https://www.youtube.com/channel/UC9OeZkIwhzfv-_Cb7fCikLQ/videos
https://www.youtube.com/watch?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&v=aircAruvnKk
https://www.youtube.com/watch?list=PLxt59R_fWVzT9bDxA76AHm3ig0Gg9S3So&v=ZzWaow1Rvho
When computer software automatically generates output that is not identical to its owntext, some of which is potentially copyrightable and some of which is not, difficult problemsarise in deciding to whom ownership rights in the output should be allocated. Applying thetraditional authorship tests of copyright law does not yield a clear solution to this problem. Inthis Article, Professor Samuelson argues that allocating rights in computer-generated outputto the user of the generator program is the soundest solution to the dilemma because it is theone most compatible with traditional doctrine and the policies that underlie copyright law.
Wildfire is a free and user-friendly image-processing software, mostly known for its sophisticated flame-fractal-generator. It is Java-based, open-source and runs on any major computer-plattform. There is also a special Android-version for mobile devices.

A Physical Book makes a digitized book “physical” by rendering it in a simulated space where properties like gravity, friction, and velocity all apply. The program randomly perturbs the letters, then takes a snapshot at a point in time, re-assembling the images into a new, “un-digitized” book.
The raw, uncorrected scanned text of The Up-To-Date Sandwich Book: 400 Ways to Make a Sandwich (1909) is re-imagined as this 251 page (50,964 words) book:

A Physical Book uses the web-based game engine Phaser. Each page of the book is rendered into an invisible <div> (to produce correct leading and line-height), then copied into the Phaser game world with each letter instantiated as a distinct addressable sprite.
For each page, one of a dozen transformations is applied to give the text varying physical properties, such as mass, acceleration, collision, or opacity.
On page load, the requested chapter number is rendered, the transformation is assigned, and the world is allowed to run. A Selenium wrapper script calls all 500 pages in succession, taking a screenshot at a random point in the animation:

The final book is rendered in a two-page spread PDF.
A credit card sized board, mounted in a wooden box. Musical instrument for your active relaxation, plus open platform for experiments with sound and music making.
https://www.kickstarter.com/projects/967276512/gecho-loopsynth-a-modern-equivalent-of-the-music-b

An open source collection of 20+ computational design tools for Clojure & Clojurescript by Karsten Schmidt.
In active development since 2012, and totalling almost 39,000 lines of code, the libraries address concepts related to many displines, from animation, generative design, data analysis / validation / visualization with SVG and WebGL, interactive installations, 2d / 3d geometry, digital fabrication, voxel modeling, rendering, linked data graphs & querying, encryption, OpenCL computing etc.
Many of the thi.ng projects (especially the larger ones) are written in a literate programming style and include extensive documentation, diagrams and tests, directly in the source code on GitHub. Each library can be used individually. All projects are licensed under the Apache Software License 2.0.
https://github.com/sirxemic/fractal-paint
Online little tool to create fractal-ish images from simple drawings using HTML5 canvases.
Artificial Neural Networks have spurred remarkable recent progress in image classification and speech recognition. But even though these are very useful tools based on well-known mathematical methods, we actually understand surprisingly little of why certain models work and others don’t. So let’s take a look at some simple techniques for peeking inside these networks.
We train an artificial neural network by showing it millions of training examples and gradually adjusting the network parameters until it gives the classifications we want. The network typically consists of 10-30 stacked layers of artificial neurons. Each image is fed into the input layer, which then talks to the next layer, until eventually the “output” layer is reached. The network’s “answer” comes from this final output layer.
One of the challenges of neural networks is understanding what exactly goes on at each layer. We know that after training, each layer progressively extracts higher and higher-level features of the image, until the final layer essentially makes a decision on what the image shows. For example, the first layer maybe looks for edges or corners. Intermediate layers interpret the basic features to look for overall shapes or components, like a door or a leaf. The final few layers assemble those into complete interpretations—these neurons activate in response to very complex things such as entire buildings or trees.
One way to visualize what goes on is to turn the network upside down and ask it to enhance an input image in such a way as to elicit a particular interpretation. Say you want to know what sort of image would result in “Banana.” Start with an image full of random noise, then gradually tweak the image towards what the neural net considers a banana (see related work in [1], [2], [3], [4]). By itself, that doesn’t work very well, but it does if we impose a prior constraint that the image should have similar statistics to natural images, such as neighboring pixels needing to be correlated. 
The Library of Babel is a place for scholars to do research, for artists and writers to seek inspiration, for anyone with curiosity or a sense of humor to reflect on the weirdness of existence - in short, it’s just like any other library. If completed, it would contain every possible combination of 1,312,000 characters, including lower case letters, space, comma, and period. Thus, it would contain every book that ever has been written, and every book that ever could be - including every play, every song, every scientific paper, every legal decision, every constitution, every piece of scripture, and so on. At present it contains all possible pages of 3200 characters, about 104677 books.
Since I imagine the question will present itself in some visitors’ minds (a certain amount of distrust of the virtual is inevitable) I’ll head off any doubts: any text you find in any location of the library will be in the same place in perpetuity. We do not simply generate and store books as they are requested - in fact, the storage demands would make that impossible. Every possible permutation of letters is accessible at this very moment in one of the library's books, only awaiting its discovery. We encourage those who find strange concatenations among the variations of letters to write about their discoveries in the forum, so future generations may benefit from their research.

Fragmentarium is an open source, cross-platform IDE for exploring pixel based graphics on the GPU. It is inspired by Adobe's Pixel Bender, but uses GLSL, and is created specifically with fractals and generative systems in mind.

"Deleuze and the Use of the Genetic Algorithm in Architecture", Speaker: Manuel Delanda, Date: April 9, 2004, Art and Technology Lecture Series
Born in 1982. His works, centralising in real-time processed, computer programmed audio visual installations, have been shown at national and international art exhibitions as well as the Media Art Festivals. He is a recipient of many awards including the Excellence Prize at the Japan Media Art Festival in 2004, and the Award of Distinction at Prix Ars Electronica in 2008. Having been involved in a wide range of activities, he has worked on a concert piece production for Ryoji Ikeda, collaborated with Yoshihide Otomo, Yuki Kimura and Benedict Drew, participated in the Lexus Art Exhibition at Milan Design week. and has started live performance as Typingmonkeys.
A selection of links about generative and new media art by Marius Watz
Do you hate having to write your artist statement? Generate your own here for free, and if you don't like it, generate another one. For use with funding applications, exhibitions, curriculum vitae, websites ...
Mandelbulbs are a new class of 3D Mandelbrot fractals. Unlike many other 3D fractals the Mandelbulb continues to reveal finer details the closer you look.
Otomata is a generative sequencer.
It employs a cellular automaton type logic
Okapi is an open-source framework for building digital, generative art in HTML5.
The embedding of the subject in a parametric figuration can bring us back the responsibility to our environment. The recognition of the consequences of our (own and other) acting in space can be a key concept for orientation, integration and the understan

This computer-driven sentence-generator, using rules and lexicon written by the artist, invents and writes a new line of text, and displays it on the sign when triggered by a motion detector.
Generative drawing dream.
Let's get flurrious, create snowflakes..
Fractal 4D is a simple and very useful Adobe AIR app that enables you to draw beatiful fractal swirls.
A cadKIT for Processing (v1.0) for Object Oriented Geometry. Based on (anar+) parametric modeling scheme is a KIT of libraries.
Stripgenerator is free of charge project created to embrace the internet blogging and strip creation culture, helping the people with no drawing abilities to express their opinions via strips. Yeah, I am one of them as well.
The ad generator is a generative artwork that explores how advertising uses and manipulates language. Words and semantic structures from real corporate slogans are remixed and randomized to generate invented slogans.
A short film made by interactivearchitecture.org on the VIDA 11.0 Exhibition held in Madrid February 2009. It includes the work of Philip Beesley & Rob Gorbet, Chico MacMurtie, Jed Berk, Chris Sugrue, Damian Stewart and Ruairi Glynn.
Build, Share, Download Fonts





