
Today's culture is biased towards business. I discuss culture without paying any attention to what sells. I am interested in great artists, musicians, writers, etc, regardless of how the business and the establishment perceives them. I also try to apply a historical perspective: history is my main interest.
A free educational site that progressively introduces you to the world of computer graphics.
Our application programming approach guides you through small, easy-to-compile programs.
We’ve dispensed with unnecessary technical jargon in favor of everyday language.
For informational purposes only
This is a fluid document, compiled from different notes/docs, originally started in ~2008, having grown slowly from my more general manifesto of that period and frequently been revised to help steer my own practice (the artistic parts) ever since.
All of the things listed here are "soft" guidelines & considerations, not an exhaustive set of hard rules! Various omissions and exceptions do exist, and the latter are explicitly encouraged! Yet, I do not imagine there'll be even minor agreement about these highly subjective, personal stances — in fact I'm very much expecting the opposite... So I'm also not publishing these bullet points to start any form of debate, but, after all these years, it's important for me to openly document how I myself have been approaching generative art projects, the topics & goals I've been trying to research & learn about, also including some of the hard lessons learned, in the hope some of these considerations might be useful for others too.
Since that list already has become rather long, there're also a bunch of other considerations & clarifications I've had to omit for now. Please keep that in mind when reading, and if some sections are maybe a little too brief/unclear...
Our wiki is a comprehensive encyclopedia of online and offline aesthetics! We are a community dedicated to the identification, observation, and documentation of visual schemata.
What is an aesthetic? Why does everyone always argue about what aesthetics should be on this wiki?
The short answer: A collection of visual schema that creates a "mood."
Some types of aesthetics include:
Aesthetics originated from Internet communities (Ex: Cottagecore, Dark Academia)
National cultures (Americana, Traditional Polish) Note: Most articles that try to describe a national culture will be deleted. These articles should have a higher quality and risk stereotyping a nation.
Genres of fiction with established visual tropes (Ex: Cyberpunk, Gothic)
Holidays with iconic imagery and colors (Ex: Christmas, Halloween)
Locations that have expected activities, components, and types of people (Ex: Fanfare, Urbancore)
Music genres with consistent visual motifs present in cover art, music videos, etc (Ex: City Pop, Emo)
This does not mean all music genres should be present. For example, Pop and Alternative bands' do not have shared visual traits.
Periods of history with distinct visuals (Ex: Victorian, Y2K)
Stereotypes (Ex: Brocore, VSCO)
Subcultures that share music genres and fashion styles (Ex: Raver, Skinheads)The long answer:
The word "aesthetic" originated as the philosophical discussion about what beauty is, how we should approach it, and why it exists. However, Millennials and Generation Z started using that term as an adjective that describes what they personally consider beautiful. For example: "After Denise finished watching The Virgin Suicides, she said, 'Wow. That was so aesthetic.'"
Aesthetics have now come to mean a collection of images, colors, objects, music, and writings that creates a specific emotion, purpose, and community. It is largely dependent on personal taste, cultural background, and exposure to different pieces of media. This definition is not official and can be debated. There is currently no dictionary definition that captures the complexity of this phenomenon, which arose in the Internet youth. Rather, people who participate in the community "know it when they see it." These elements are constantly debated, as the opinion on whether or not some aesthetics exist or are valid is constantly debated. This is especially true since everyone's own personal life factors into their opinions.
Here is an example of a debate that is going on within the community. Whether or not Lolita is an aesthetic varies on what counts as visual elements. On one hand, lace, petticoats, and bows are valid elements of visual schema. Those elements combine to spark feelings of kawaii, de-sexualization, rebellion, and appreciation of antique. On the other hand, aesthetics are made up of elements other than fashion, such as home decor or music. Fashion is the visual element, rather than the components making up the coord/outfit. That element is part of broader schemas such as Goth and Victorian. What counts as an element and what qualifies as sparking an emotion is a complicated subject.
So right now, the subject is trying to be defined by the community. What either fits into a larger schema or is distinct enough to warrant its own aesthetic is difficult to say and would depend on who you are asking.
Clip retrieval works by converting the text query to a CLIP embedding , then using that embedding to query a knn index of clip image embedddings
https://github.com/rom1504/clip-retrieval

The road to wisdom?
-- Well, it's plain
and simple to express:
Err
and err
and err again
but less
and less
and less.Hence the name LessWrong. We might never attain perfect understanding of the world, but we can at least strive to become less and less wrong each day.
We are a community dedicated to improving our reasoning and decision-making. We seek to hold true beliefs and to be effective at accomplishing our goals. More generally, we work to develop and practice the art of human rationality.[1]
To that end, LessWrong is a place to 1) develop and train rationality, and 2) apply one’s rationality to real-world problems.
“Although our study doesn’t present ways to mitigate negative hunger-induced emotions, research suggests that being able to label an emotion can help people to regulate it, such as by recognising that we feel angry simply because we are hungry. Therefore, greater awareness of being ‘hangry’ could reduce the likelihood that hunger results in negative emotions and behaviours in individuals.”



The Digital Curator application allows you to explore the art collections of Central European museums and search for artworks based on specific motifs.
Users of the application can build their combination of objects and reveal how often the subject has occurred across the centuries, view graphics, drawings, or paintings that represent it in different epochs, and compare data with other themes.
The Digital Curator offers a quantitative view of cultural history based on the frequency of symbols and iconographic themes in many artifacts, not on a detailed observation of individual items. This distant viewing can be especially useful if our interest is aimed at exploring a genre, rather than a specific work, to understand the overall social conditions, rather than the life of a particular artist, or to interpret the overall political situation, rather than the views of the selected author. Exploring big cultural-historical data may bring new insights into abstract social phenomena such as cultural and economic influence, canon issues, the relationship between the center and the periphery, or the functioning of the art market. It can also help us better observe the migration of motifs and their takeover across centuries and distant regions.
The Digital Curator database now contains 196 116 works from the collections of 91 museums from Austria, Bavaria, the Czech Republic, and Slovakia. 71 410 of these works are available under an open license, so it is possible to view them online. Other works are used only as a basis for statistics, presenting the frequency of occurrence of motifs. The AI library for machine learning TensorFlow and the computer service Google Cloud including the tool Google Cloud Vision were used for the automatic detection of the depicted motifs. Data search and storage is performed using the ElasticSearch database and the operation of the application is provided by the Google App Engine service.
Implementation was carried out with the kind support of the UMPRUM, Academy of Arts, Architecture and Design in Prague , the Ministry of Education of the Czech Republic the Slovak National Gallery, and the BlueGhost digital agency. Thanks also go to many museums that made it possible to use their digitized collections, and to Richard Prajer, Radim Hašek, and Eva Škvárová who helped with the development of the application and the preparation of the database.
The project was designed by Lukas Pilka in 2019-22.
This is a chronological gallery of physical visualizations and related artifacts, maintained by Pierre Dragicevic and Yvonne Jansen.
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.208.6726&rep=rep1&type=pdf
Bitmap Image to 'Pixel Perfect' Vector Graphic or 3D model
The HTML5 application on this page converts your bitmap image online into a Scalable Vector Graphics or 3D model.
The result is 'pixel perfect'/lossless.

The Voynichese project (VP) defines a simple syntax for querying words in the Voynich Manuscript. While this syntax is only used internally, by the VP's query processor, it's important to be aware of how it operates in order to effectively query the manuscript.
Note that, unlike most query languages, Voynichese queries are evaluated at the word level. As such, word delimiters like whitespace and punctuation are not allowed.
Voynichese queries may use the following characters:
a,c,d,e,f,g,h,i,k,l,m,n,o,p,q,r,s,t,v,x,y,z,*,^,$
The characters a-z each match the corresponding EVA character.
The wildcard character "*" matches one or more EVA characters. Note that the wildcard may also be represented as a dash "-", for example when used in an URL.
The "^" character matches the start of a word.
The "$" character matches the end of a word.
For example, the query ^daiin$ will exactly match the EVA word daiin, whereas the query daiin (excluding the ^ and $ symbols) will match any EVA word containing daiin, such as chodaiindy.
Welcome to Exploring Technology, a wishful remedy to the increasing knowledge gap between machine builders and machine users.
Learn about :
A-Frame
Arduino
AxiDraw
Bitsy
Cables
Cinema 4D
Circuit
GitHub
Colab
Glitch
Hubs
Hydra
Laser Cutting
Lightform
Lights
Machine Learning
Makey Makey
NFT
Node
Photogrammetry
Processing
Projectors
Raspberry Pi
Resolume
Tone
Spark
Web
Luminous-Lint is used worldwide by curators, educators, photography students, photohistorians, collectors and photographers to better understand the many histories of photography.


Carefully curated list of awesome creative coding resources primarily for beginners/intermediates :
![]()

To the extent possible under law, Terkel Gjervig has waived all copyright and related or neighboring rights to this work.
All Sci Fi novels published since 1900 were scraped from Good Reads, and for each novel, all reader comments, plot descriptions, and user-generated tags were compiled. Keywords and concepts were added to each novel by parsing the text described above and mapping them to a curated dictionary of SciFi keywords and concepts. 2,633 novels published since 1990 had at least 50 reviews and contained at least one keyword from the keyword corpus.
After keyword enhancement, a book network was created by linking novels if they share similar keyword. Network clusters identify Keyword Themes - or groups of similar books that are labeled most commonly shared keywords in the group.
The network was generated using the open source python 'tag2network' package, and visualized here using 'openmappr''. The scripts for analyzing this dataset are available at https://github.com/ericberlow/SciFi
This is a collaborative project of Bethanie Maples, Srini Kadamati, and Eric Berlow
NOTE - This visualization performs best in Chrome and Safari browsers full screen - and is not optimized for the small screens of mobile devices.
How to Navigate this Network:
Click on any node to to see more details about it.
Click the whitespace or 'Reset' button to clear any selection.
Use the Snapshots panel to navigate between views.
Use the Filters panel to select nodes by any combination of attributes.
Click the 'Subset' button to restrict the data to the selected nodes - The Filters panel will then show a summary of that subset.
Use the List panel to see a sortable list of any nodes selected or subset. You can also browse their details one by one by clicking on them in the list.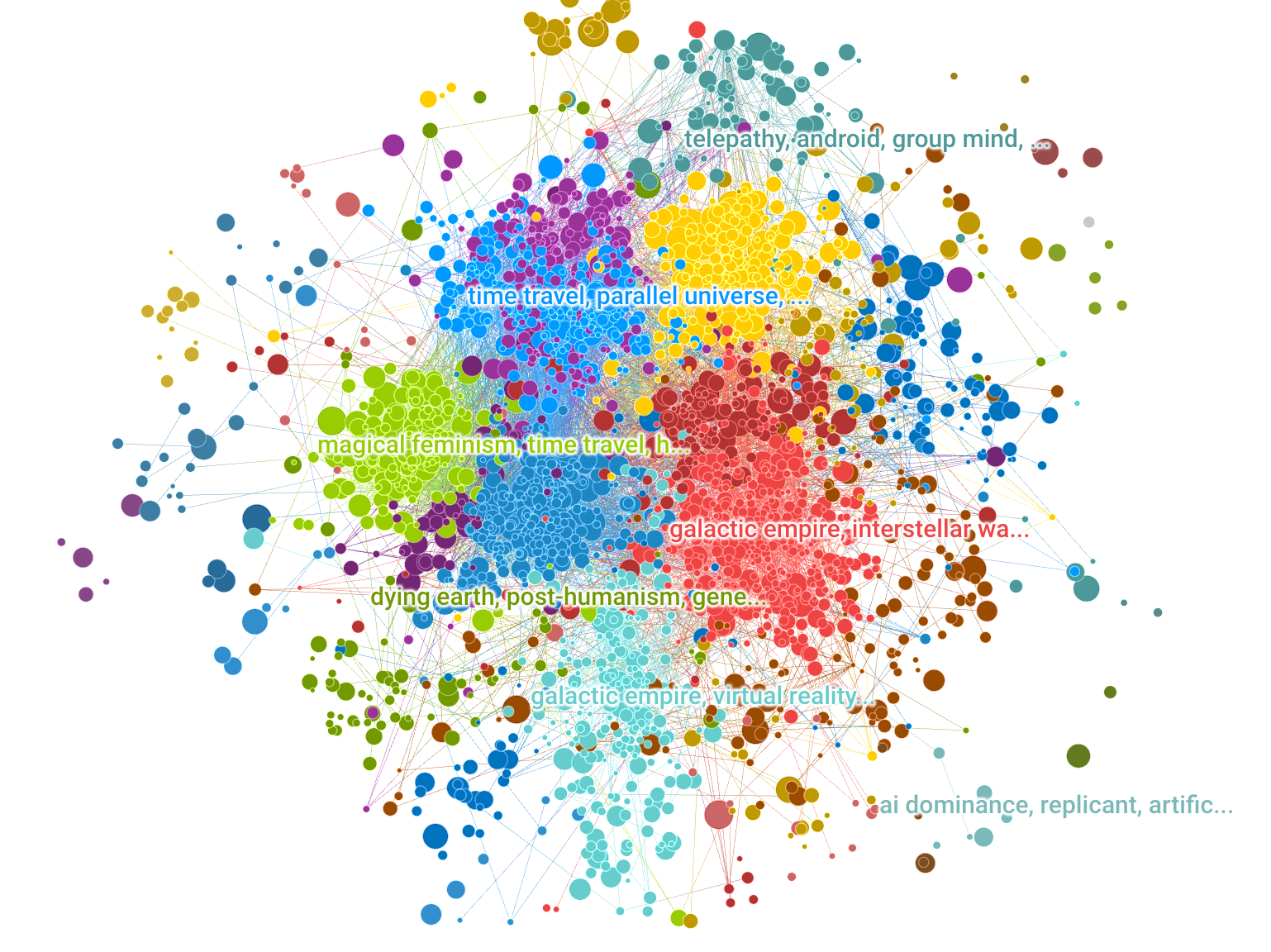
All The Tropes is a community-edited wiki website dedicated to discussing Creators, Works, and Tropes -- the people, projects and patterns of creative writing in all kinds of entertainment: television, literature, movies, video games, and more.
Can I use the art I find here? How should I credit the artist?
Yes, you can use any of the art submitted to this site. Even in commercial projects. Just be sure to adhere to the license terms. Artists often indicate how they would like to be credited in the "Copyright/Attribution Notice:" section of the submission. You can find this between the submission's description and the list of downloadable files. If no Copyright/Attribution Notice instructions are given, a good way to credit an author for any asset is to put the following text in your game's credits file and on your game's credits screen:
"[asset name]" by [author name] licensed [license(s)]: [asset url]For example:
"Whispers of Avalon: Grassland Tileset" by Leonard Pabin licensed CC-BY 3.0, GPL 2.0, or GPL 3.0: https://opengameart.org/node/3009OpenGameArt Search + Reverse Image Search
Hint: Start search term with http(s):// for reverse image search.
The Collections database consists of entries for more than 480,000 works in the Musée du Louvre and Musée National Eugène-Delacroix. Updated on a daily basis, it is the result of the continuous research and documentation efforts carried out by teams of experts from both museums.
Welcome to the Historical Dictionary of Science Fiction. This work-in-progress is a comprehensive quotation-based dictionary of the language of science fiction. The HD/SF is an offshoot of a project begun by the Oxford English Dictionary (though it is no longer formally affiliated with it). It is edited by Jesse Sheidlower.
Welcome to Smithsonian Open Access, where you can download, share, and reuse millions of the Smithsonian’s images—right now, without asking. With new platforms and tools, you have easier access to more than 3 million 2D and 3D digital items from our collections—with many more to come. This includes images and data from across the Smithsonian’s 19 museums, nine research centers, libraries, archives, and the National Zoo.
What will you create?

The Standard Ebooks project is a volunteer driven, not-for-profit effort to produce a collection of high quality, carefully formatted, accessible, open source, and free public domain ebooks that meet or exceed the quality of commercially produced ebooks. The text and cover art in our ebooks is already believed to be in the public domain, and Standard Ebooks dedicates its own work to the public domain, thus releasing the entirety of each ebook file into the public domain. All the ebooks we produce are distributed free of cost and free of U.S. copyright restrictions.
The Hidden Palace is a community dedicated to the preservation of video game development media

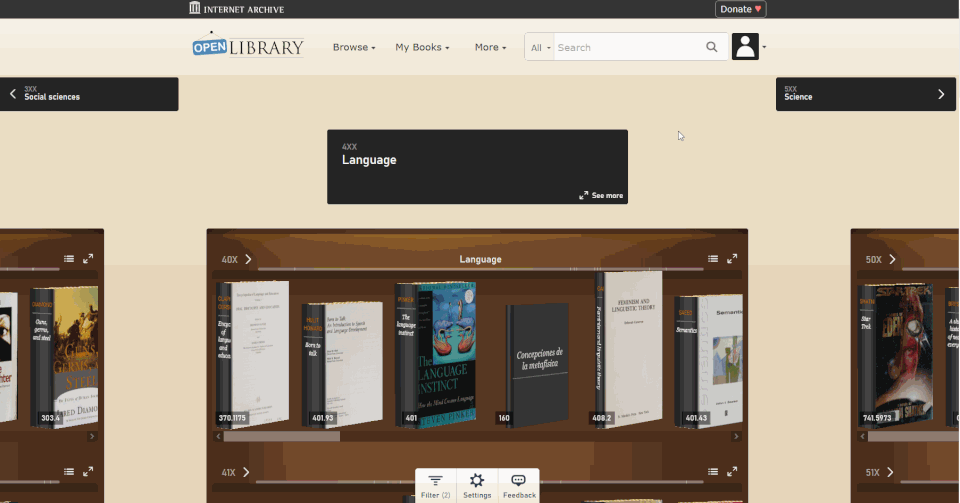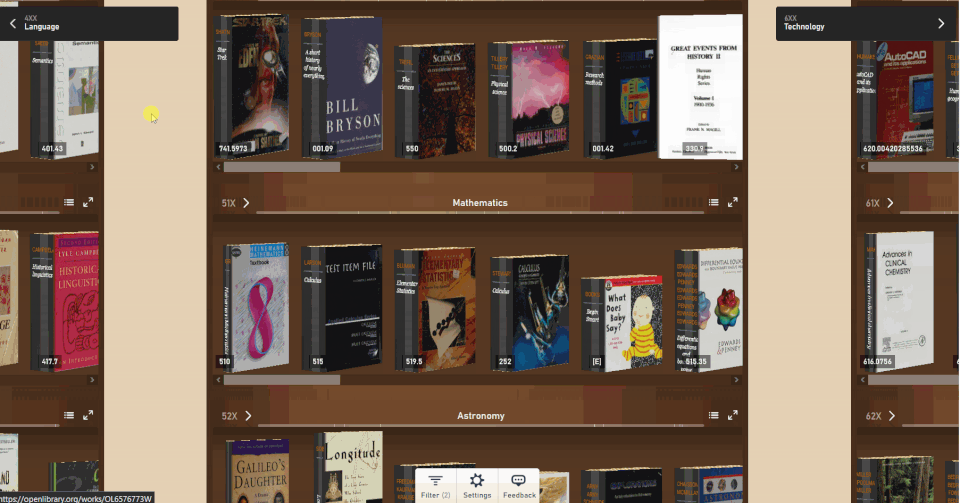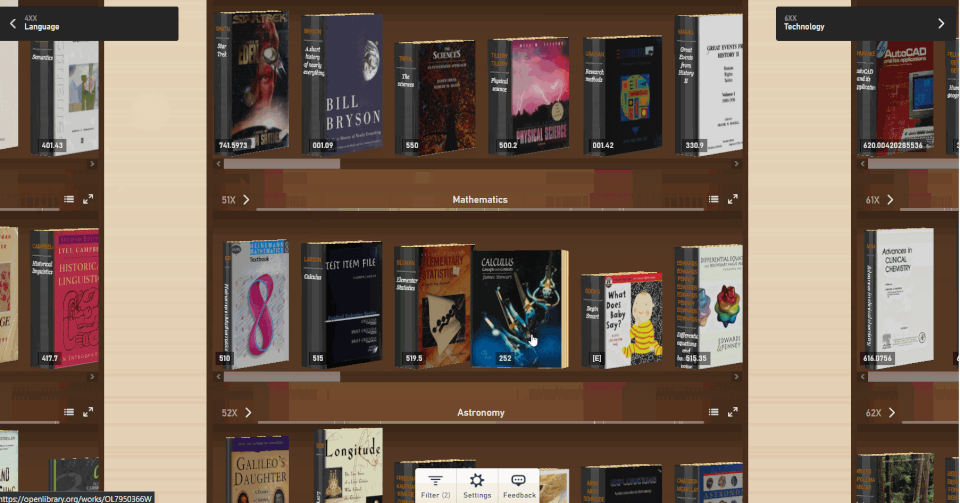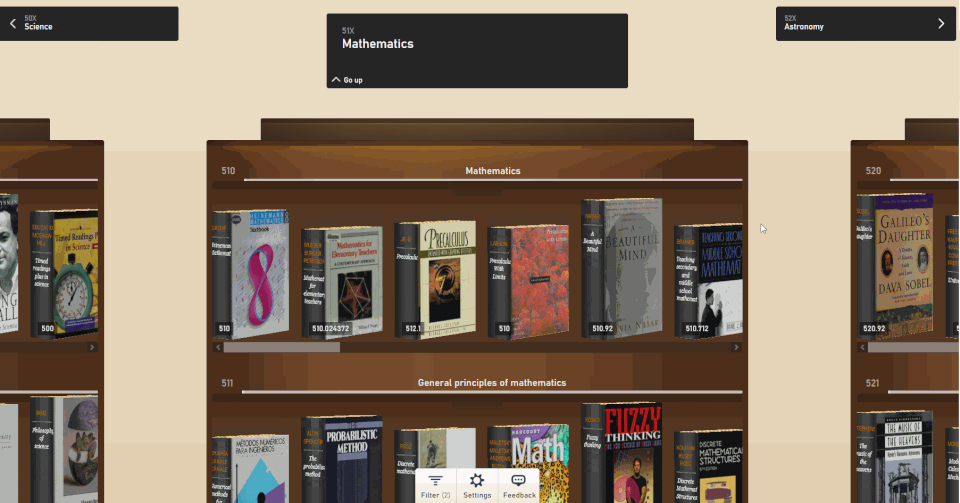
Enter the Open Library Explorer, Cami’s new experiment for browsing more than 4 million books in the Internet Archive’s Open Library. Still in beta, Open Library Explorer is able to harness the Dewey Decimal or Library of Congress classification systems to recreate virtually the experience of browsing the bookshelves at a physical library. Open Library Explorer enables readers to scan bookshelves left to right by subject, up and down for subclassifications. Switch a filter and suddenly the bookshelves are full of juvenile books. Type in “subject: biography” and you see nothing but biographies arranged by subject matter.
Why recreate a physical library experience in your browser?
Now that classrooms and libraries are once again shuttered, families are turning online for their educational and entertainment needs. With demand for digital books at an all-time high, the Open Library team was inspired to give readers something closer to what they enjoy in the physical world. Something that puts the power of discovery back into the hands of patrons.
Escaping the Algorithmic Bubble
One problem with online platforms is the way they guide you to new content. For music, movies, or books, Spotify, Netflix and Amazon use complicated recommendation algorithms to suggest what you should encounter next. But those algorithms are driven by the media you have already consumed. They put you into a “filter bubble” where you only see books similar to those you’ve already read. Cami and his team devised the Open Library Explorer as an alternative to recommendation engines. With the Open Library Explorer, you are free to dive deeper and deeper into the stacks. Where you go is driven by you, not by an algorithm..
Zoom out to get an ever expanding view of your library
Change the setting to make your books 3D, so you can see just how thick each volume is.
Cool New Features
By clicking on the Settings gear, you can customize the look and feel of your shelves. Hit the 3D options and you can pick out the 600-page books immediately, just by the thickness of the spine. When a title catches your eye, click on the book to see whether Open Library has an edition you can preview or borrow. For more than 4 million books, borrowing a copy in your browser is just a few clicks away.
Ready to enter the library? Click here, and be sure to share feedback so the Open Library team can make it even better.
The papers summarized here are mainly from 2017 onwards.
Please refer to the Survey paper(Image Aesthetic Assessment:An Experimental Survey) before 2016.
Optical illusions don’t “trick the eye” nor “fool the brain”, nor reveal that “our brain sucks”, … but are fascinating!
They also teach us about our visual perception, and its limitations. My selection emphazises beauty and interactive experiments; I also attempt explanations of the underlying visual mechanisms where possible.
Returning visitor? Check →here for History/News
»Optical illusion« sounds derogative, as if exposing a malfunction of the visual system. Rather, I view these phenomena as highlighting particular good adaptations of our visual system to its experience with standard viewing situations. These experiences are based on normal visual conditions, and thus under unusual contexts can lead to inappropriate interpretations of a visual scene (=“Bayesian interpretation of perception”).
If you are not a vision scientist, you might find my explanations too highbrow. That is not on purpose, but vision research simply is not trivial, like any science. So, if an explanation seems gibberish, simply enjoy the phenomenon 😉.
A showcase with creative machine learning experiments










Web scraping describes techniques for automatically downloading and processing web content, or converting online text and other media into structured data that can then be used for various purposes. In short, the user writes a program to browse and analyze the web on their behalf, rather than doing so manually. This is a common practice in silicon valley, where open html pages are transformed into private property: Facebook began as a (horny) web scraping project, as did Google and all other search engines. Web scraping is also frequently used to acquire the massive datasets needed to train machine learning models, and has become an important research tool in fields such as journalism and sociology.
I define "scrapism" as the practice of web scraping for artistic, emotional, and critical ends. It combines aspects of data journalism, conceptual art, and hoarding, and offers a methodology to make sense of a world in which everything we do is mediated by internet companies. These companies surveill us, vacuum up every trace we leave behind, exploit our experiences and interject themselves into every possible moment. But in turn they also leave their own traces online, traces which when collected, filtered, and sorted can reveal (and possibly even alter) power relations. The premise of scrapism is that everything we need to know about power is online, hiding in plain sight.
This is a work-in-progress guide to web scraping as an artistic and critical practice, created by Sam Lavigne. I will be updating it over the coming months! I'll also be doing occasional live demos either on Twitch or YoutTube.





Conceptual comics is an archive of works that are unaffiliated with the commonly accepted history of the comics medium. It is a resonating chamber for conceptual works and unconventional practices that are little known outside of our community but also a springboard for establishing the conditions for an affective lineage between similarly minded practitioners. The variety of the collected material expresses the curator’s choice for a non uniform consistency and claim instead for a perpetual becoming of the medium. Nevertheless, these works share with each other many common issues and urgencies, alternating between material self-reflexivity and critical exhaustion. They operate on the margins of distribution and reception and their unlocatedness in the medium's spectrum is more than an abstraction: artists uncomfortable with the entrenched roles invite readers, in the absence of critical discourse, to engage with the works in non-specified, at times forensic, ways of examination. I argue that this condition, more than a minor drawback of a normative industry, induces new behaviours and forms of social relationships. Each of the works that are featured in this collection explores the very substrate of its medium not as a culturally neutral site, but as a way to build alternative historiographies, replete with its own material properties and signifying potentials. They propose to examine how social and economic forces and their related sets of activities and commercial, communicative and other routines compose the media’s meaning-signifying trajectory. The rainforest of pulp production, the printer’s studio, the readers’ column and the landfill are not simply the industry's geographies but are technologies of inscription in their own right. They are the integral elements of a material language that actively shapes the medium and challenges the reader to negotiate meaning through different distributions of transparency over opacity in its products. This collection proposes to equally embrace the real, the unclaimed, the anticipated and the fictional practices, in their constant materialisation, and reflect on their specific sites of production in their potential to register meaning and organise discourse based on the inscriptions of this material language.
About Ilan Manouach
Ilan David Manouach is a researcher and a multidisciplinary artist with a specific interest in conceptual and post-digital art. He currently holds a PhD position at the Aalto University in Helsinki (adv. Craig Dworkin) where he examines the intersections of contemporary graphic literature and XXIst century’s technological disruptions. He is mostly known for Shapereader, a system for tactile storytelling specifically designed for blind and partially sighted readers/makers of comics. He is also the founder and creative director of Applied Memetic an organization that researches the political repercussions of generative art and highlights the urgency for a new media-rich internet literacy. His work has been written about in Hyperallergic, World Literature Today, Wired, Le Monde, The Comics Journal, du9, 50 Watts and Kenneth Goldsmith’s Wasting Time on the Internet. For a fuller documentation on the above projects, the Brussels-based non-profit Echo Chamber is responsible for producing, fundraising, documenting and archiving Manouach’s research on contemporary comics, that has been presented in solo exhibitions to important festivals, museums and galleries worldwide. He is an Onassis Digital Fellow and a Kone alumnus and he works as a strategy consultant for the Onassis Foundation visibility through its newly founded publishing arm.
Table of Contents
Creative Coding History
Modern Creative Coding Uses
Graphics Concepts
Creative Coding Environments and Libraries
Communication Protocols
Multimedia Tools
Unique Displays and Touchscreens
Hardware
Other output options
More resourcesComprehensive overview of existing tools, strategies and thoughts on interacting with your data
TLDR: when I read I try to read actively, which for me mainly involves using various tools to annotate content: highlight and leave notes as I read. I've programmed data providers that parse them and provide nice interface to interact with this data from other tools. My automated scripts use them to render these annotations in human readable and searchable plaintext and generate TODOs/spaced repetition items.
In this post I'm gonna elaborate on all of that and give some motivation, review of these tools (mainly with the focus on open source thus extendable software) and my vision on how they could work in an ideal world. I won't try to convince you that my method of reading and interacting with information is superior for you: it doesn't have to be, and there are people out there more eloquent than me who do that. I assume you want this too and wondering about the practical details.
This database* is an ongoing project to aggregate tools and resources for artists, engineers, curators & researchers interested in incorporating machine learning (ML) and other forms of artificial intelligence (AI) into their practice. Resources in the database come from our partners and network; tools cover a broad spectrum of possibilities presented by the current advances in ML like enabling users to generate images from their own data, create interactive artworks, draft texts or recognise objects. Most of the tools require some coding skills, however, we’ve noted ones that don’t. Beginners are encouraged to turn to RunwayML or entries tagged as courses.
*This database isn’t comprehensive—it's a growing collection of research commissioned & collected by the Creative AI Lab. The latest tools were selected by Luba Elliott. Check back for new entries.
Via : https://docs.google.com/document/d/1TkusCE5mS4tuTYoBwaTV4aJKdSVsf9jFKsGJCx8M05c/edit
This is a list of smaller tools that might be useful in building your game/website/interactive project. Although I’ve mostly also included ‘standards’, this list has a focus on artful tools & toys that are as fun to use as they are functional.
The goal of this list is to enable making entirely outside of closed production ecosystems or walled software gardens.
Explore the inventions, technology and ideas of science fiction writers
Date Device Name (Novel Author)
1634 Weightlessness (Kepler) (from Somnium (The Dream) by Johannes Kepler)
1638 Weightlessness in Space (from The Man in the Moone by Francis Godwin)
1638 Gansas (from The Man in the Moone by Francis Godwin)
1657 Moon Machine - very early description (from A Voyage to the Moon by Cyrano de Bergerac)
1705 Cogitator (The Chair of Reflection) (from The Consolidator by Daniel Defoe)
1726 Knowledge Engine - machine-made expertise (from Gulliver's Travels by Jonathan Swift)
1726 Geometric Modeling - eighteenth century NURBS (from Gulliver's Travels by Jonathan Swift)
1726 Bio-Energy - produce electricity from organic material (from Gulliver's Travels by Jonathan Swift)
1726 Laputa - a floating island (from Gulliver's Travels by Jonathan Swift)
1727 Androide - the original (from Cyclopaedia by Ephraim Chambers)
The new Collection online
From Dürer to the Rosetta Stone, explore 4.5 million objects.
The database is based on the British Museum's collection management tool, where we record what we know about our collection. It was created for the Museum to store information for its own use, and is therefore full of specialised terms, abbreviations and shorthand.
The Museum has been working on the database for more than 40 years and, even with more than two million records, we've only catalogued about half of the collection. We're adding and improving records every day but, even so, an object record may not have been checked. In many cases, the most recent research has not yet been added. There will be mistakes and omissions, but the Museum chooses to publish the data, rather than hold it until it is 'finished', as there will always be new information about an object. Only personal and sensitive information has been withheld.

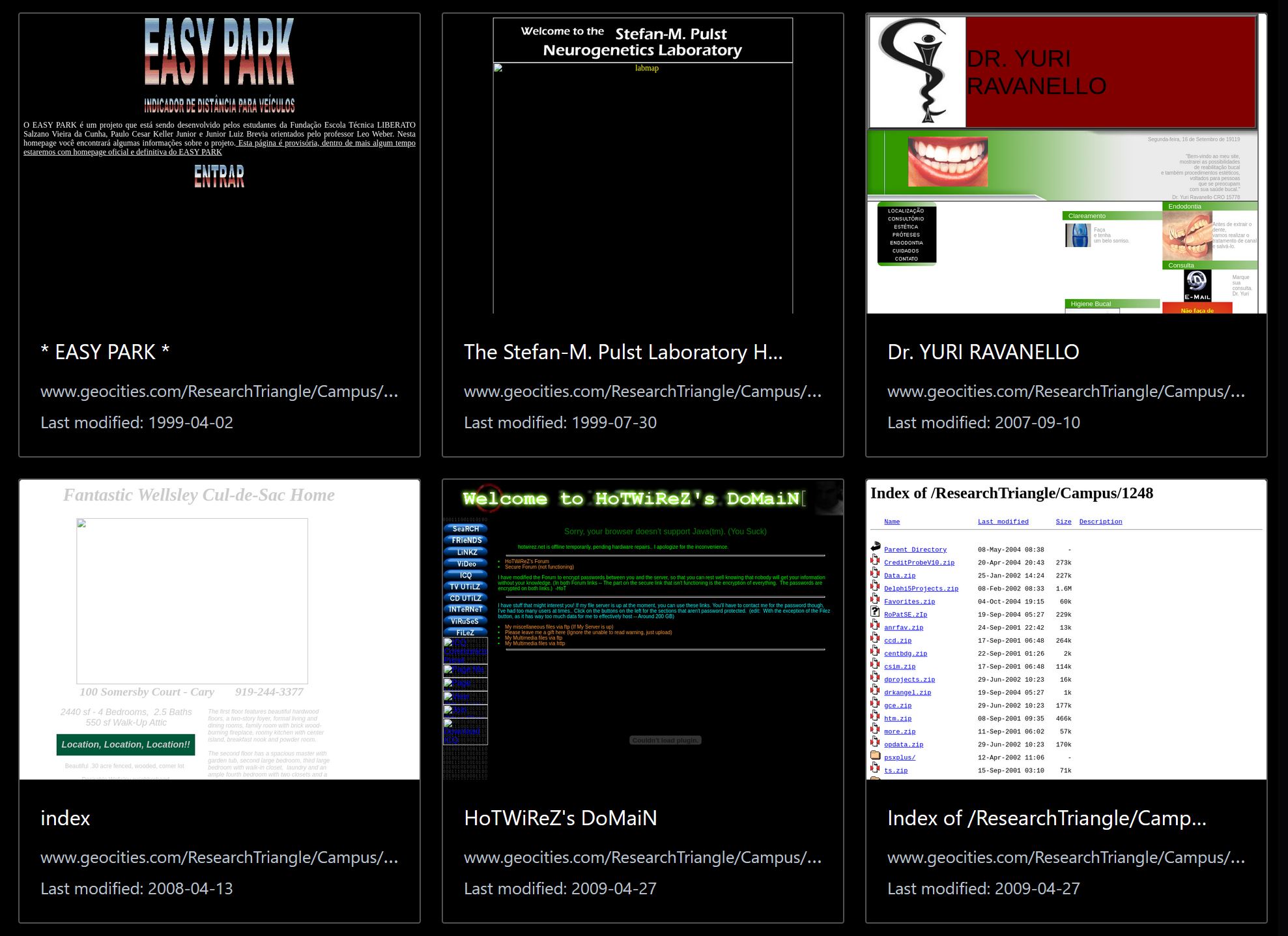
a project to excavate shut down, abandoned web ruins and restore them to surfable, accessible, searchable, remixable condition
somewhere between a library and a living museum, we're working on experimental new ways to close the gap between archival and visibility of the web that was lost
launched
geocities
myspace musicon deck
aol hometown
netscape web sites
geocities japan
FortuneCity
tbaThese 16,000 BBC Sound Effects are made available by the BBC in WAV format to download for use under the terms of the RemArc Licence. The Sound Effects are BBC copyright, but they may be used for personal, educational or research purposes, as detailed in the license.
Writing Machines is a resource dedicated to various projects related to electronic literature/books/writing/art curated by Julia Garcia
The Organization for Transformative Works (OTW) is a nonprofit organization, established by fans in 2007, to serve the interests of fans by providing access to and preserving the history of fanworks and fan culture in its myriad forms. We believe that fanworks are transformative and that transformative works are legitimate.
We are proactive and innovative in protecting and defending our work from commercial exploitation and legal challenge. We preserve our fannish economy, values, and creative expression by protecting and nurturing our fellow fans, our work, our commentary, our history, and our identity while providing the broadest possible access to fannish activity for all fans.





