
Welcome to Smithsonian Open Access, where you can download, share, and reuse millions of the Smithsonian’s images—right now, without asking. With new platforms and tools, you have easier access to more than 3 million 2D and 3D digital items from our collections—with many more to come. This includes images and data from across the Smithsonian’s 19 museums, nine research centers, libraries, archives, and the National Zoo.
What will you create?

The Standard Ebooks project is a volunteer driven, not-for-profit effort to produce a collection of high quality, carefully formatted, accessible, open source, and free public domain ebooks that meet or exceed the quality of commercially produced ebooks. The text and cover art in our ebooks is already believed to be in the public domain, and Standard Ebooks dedicates its own work to the public domain, thus releasing the entirety of each ebook file into the public domain. All the ebooks we produce are distributed free of cost and free of U.S. copyright restrictions.
The Hidden Palace is a community dedicated to the preservation of video game development media

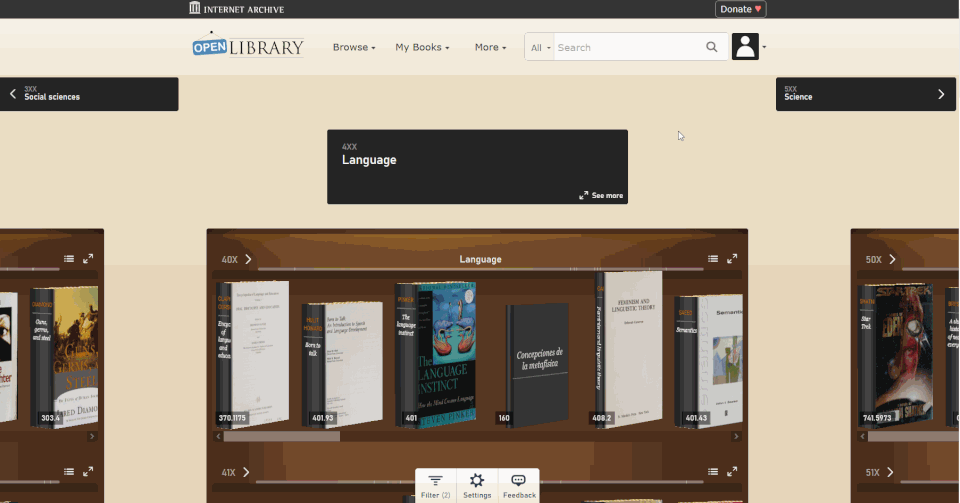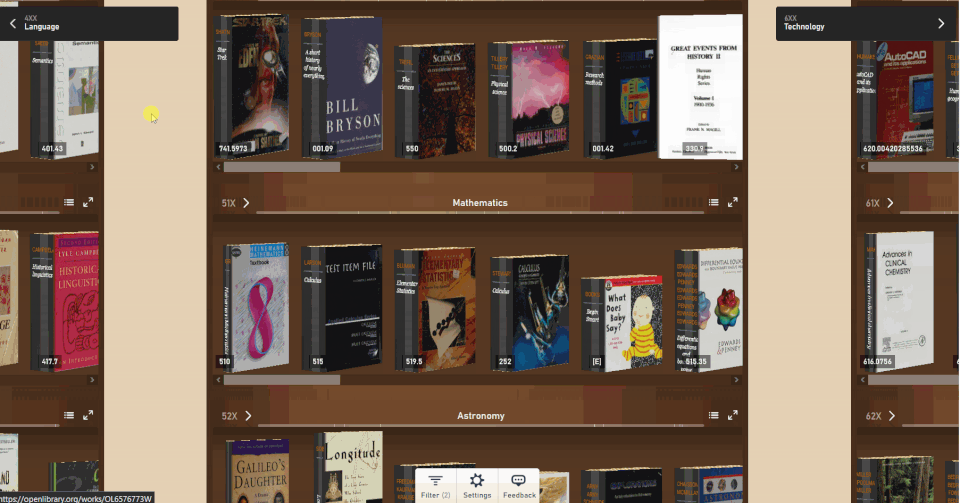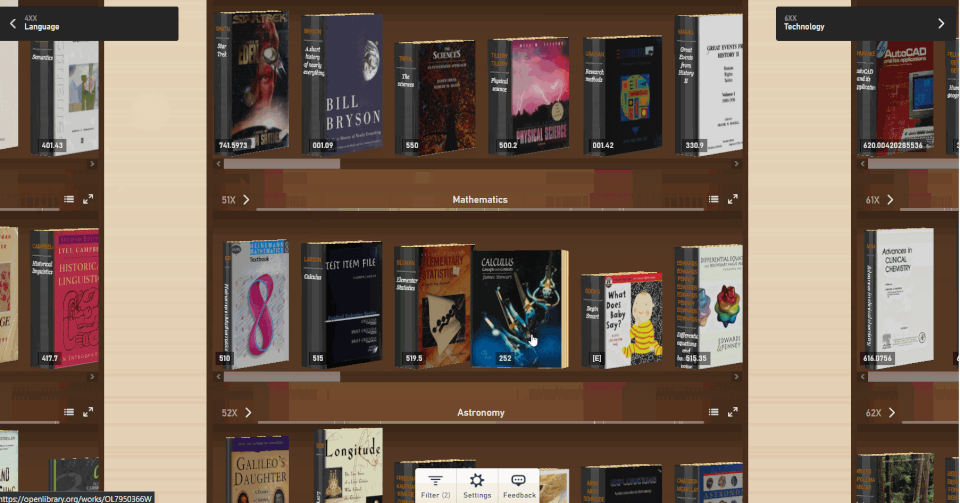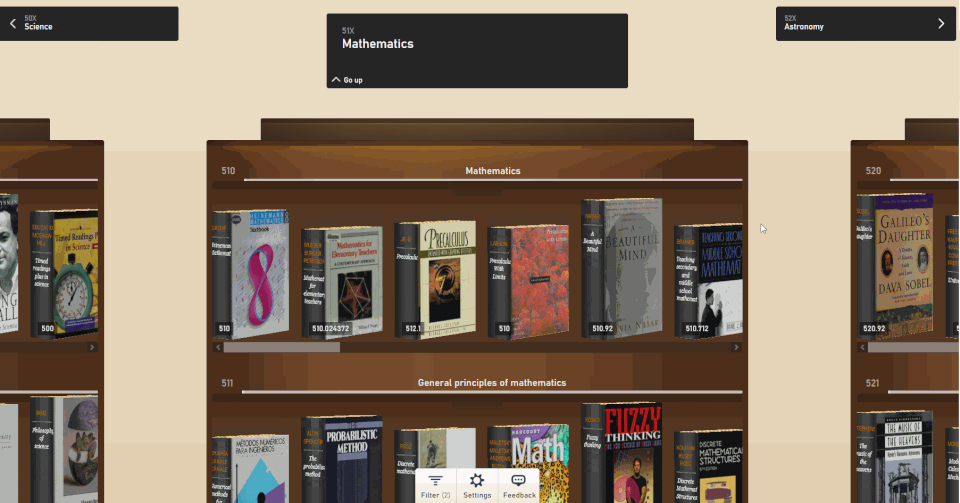
Enter the Open Library Explorer, Cami’s new experiment for browsing more than 4 million books in the Internet Archive’s Open Library. Still in beta, Open Library Explorer is able to harness the Dewey Decimal or Library of Congress classification systems to recreate virtually the experience of browsing the bookshelves at a physical library. Open Library Explorer enables readers to scan bookshelves left to right by subject, up and down for subclassifications. Switch a filter and suddenly the bookshelves are full of juvenile books. Type in “subject: biography” and you see nothing but biographies arranged by subject matter.
Why recreate a physical library experience in your browser?
Now that classrooms and libraries are once again shuttered, families are turning online for their educational and entertainment needs. With demand for digital books at an all-time high, the Open Library team was inspired to give readers something closer to what they enjoy in the physical world. Something that puts the power of discovery back into the hands of patrons.
Escaping the Algorithmic Bubble
One problem with online platforms is the way they guide you to new content. For music, movies, or books, Spotify, Netflix and Amazon use complicated recommendation algorithms to suggest what you should encounter next. But those algorithms are driven by the media you have already consumed. They put you into a “filter bubble” where you only see books similar to those you’ve already read. Cami and his team devised the Open Library Explorer as an alternative to recommendation engines. With the Open Library Explorer, you are free to dive deeper and deeper into the stacks. Where you go is driven by you, not by an algorithm..
Zoom out to get an ever expanding view of your library
Change the setting to make your books 3D, so you can see just how thick each volume is.
Cool New Features
By clicking on the Settings gear, you can customize the look and feel of your shelves. Hit the 3D options and you can pick out the 600-page books immediately, just by the thickness of the spine. When a title catches your eye, click on the book to see whether Open Library has an edition you can preview or borrow. For more than 4 million books, borrowing a copy in your browser is just a few clicks away.
Ready to enter the library? Click here, and be sure to share feedback so the Open Library team can make it even better.
The papers summarized here are mainly from 2017 onwards.
Please refer to the Survey paper(Image Aesthetic Assessment:An Experimental Survey) before 2016.
Optical illusions don’t “trick the eye” nor “fool the brain”, nor reveal that “our brain sucks”, … but are fascinating!
They also teach us about our visual perception, and its limitations. My selection emphazises beauty and interactive experiments; I also attempt explanations of the underlying visual mechanisms where possible.
Returning visitor? Check →here for History/News
»Optical illusion« sounds derogative, as if exposing a malfunction of the visual system. Rather, I view these phenomena as highlighting particular good adaptations of our visual system to its experience with standard viewing situations. These experiences are based on normal visual conditions, and thus under unusual contexts can lead to inappropriate interpretations of a visual scene (=“Bayesian interpretation of perception”).
If you are not a vision scientist, you might find my explanations too highbrow. That is not on purpose, but vision research simply is not trivial, like any science. So, if an explanation seems gibberish, simply enjoy the phenomenon 😉.
A showcase with creative machine learning experiments










Web scraping describes techniques for automatically downloading and processing web content, or converting online text and other media into structured data that can then be used for various purposes. In short, the user writes a program to browse and analyze the web on their behalf, rather than doing so manually. This is a common practice in silicon valley, where open html pages are transformed into private property: Facebook began as a (horny) web scraping project, as did Google and all other search engines. Web scraping is also frequently used to acquire the massive datasets needed to train machine learning models, and has become an important research tool in fields such as journalism and sociology.
I define "scrapism" as the practice of web scraping for artistic, emotional, and critical ends. It combines aspects of data journalism, conceptual art, and hoarding, and offers a methodology to make sense of a world in which everything we do is mediated by internet companies. These companies surveill us, vacuum up every trace we leave behind, exploit our experiences and interject themselves into every possible moment. But in turn they also leave their own traces online, traces which when collected, filtered, and sorted can reveal (and possibly even alter) power relations. The premise of scrapism is that everything we need to know about power is online, hiding in plain sight.
This is a work-in-progress guide to web scraping as an artistic and critical practice, created by Sam Lavigne. I will be updating it over the coming months! I'll also be doing occasional live demos either on Twitch or YoutTube.





Conceptual comics is an archive of works that are unaffiliated with the commonly accepted history of the comics medium. It is a resonating chamber for conceptual works and unconventional practices that are little known outside of our community but also a springboard for establishing the conditions for an affective lineage between similarly minded practitioners. The variety of the collected material expresses the curator’s choice for a non uniform consistency and claim instead for a perpetual becoming of the medium. Nevertheless, these works share with each other many common issues and urgencies, alternating between material self-reflexivity and critical exhaustion. They operate on the margins of distribution and reception and their unlocatedness in the medium's spectrum is more than an abstraction: artists uncomfortable with the entrenched roles invite readers, in the absence of critical discourse, to engage with the works in non-specified, at times forensic, ways of examination. I argue that this condition, more than a minor drawback of a normative industry, induces new behaviours and forms of social relationships. Each of the works that are featured in this collection explores the very substrate of its medium not as a culturally neutral site, but as a way to build alternative historiographies, replete with its own material properties and signifying potentials. They propose to examine how social and economic forces and their related sets of activities and commercial, communicative and other routines compose the media’s meaning-signifying trajectory. The rainforest of pulp production, the printer’s studio, the readers’ column and the landfill are not simply the industry's geographies but are technologies of inscription in their own right. They are the integral elements of a material language that actively shapes the medium and challenges the reader to negotiate meaning through different distributions of transparency over opacity in its products. This collection proposes to equally embrace the real, the unclaimed, the anticipated and the fictional practices, in their constant materialisation, and reflect on their specific sites of production in their potential to register meaning and organise discourse based on the inscriptions of this material language.
About Ilan Manouach
Ilan David Manouach is a researcher and a multidisciplinary artist with a specific interest in conceptual and post-digital art. He currently holds a PhD position at the Aalto University in Helsinki (adv. Craig Dworkin) where he examines the intersections of contemporary graphic literature and XXIst century’s technological disruptions. He is mostly known for Shapereader, a system for tactile storytelling specifically designed for blind and partially sighted readers/makers of comics. He is also the founder and creative director of Applied Memetic an organization that researches the political repercussions of generative art and highlights the urgency for a new media-rich internet literacy. His work has been written about in Hyperallergic, World Literature Today, Wired, Le Monde, The Comics Journal, du9, 50 Watts and Kenneth Goldsmith’s Wasting Time on the Internet. For a fuller documentation on the above projects, the Brussels-based non-profit Echo Chamber is responsible for producing, fundraising, documenting and archiving Manouach’s research on contemporary comics, that has been presented in solo exhibitions to important festivals, museums and galleries worldwide. He is an Onassis Digital Fellow and a Kone alumnus and he works as a strategy consultant for the Onassis Foundation visibility through its newly founded publishing arm.
Table of Contents
Creative Coding History
Modern Creative Coding Uses
Graphics Concepts
Creative Coding Environments and Libraries
Communication Protocols
Multimedia Tools
Unique Displays and Touchscreens
Hardware
Other output options
More resourcesComprehensive overview of existing tools, strategies and thoughts on interacting with your data
TLDR: when I read I try to read actively, which for me mainly involves using various tools to annotate content: highlight and leave notes as I read. I've programmed data providers that parse them and provide nice interface to interact with this data from other tools. My automated scripts use them to render these annotations in human readable and searchable plaintext and generate TODOs/spaced repetition items.
In this post I'm gonna elaborate on all of that and give some motivation, review of these tools (mainly with the focus on open source thus extendable software) and my vision on how they could work in an ideal world. I won't try to convince you that my method of reading and interacting with information is superior for you: it doesn't have to be, and there are people out there more eloquent than me who do that. I assume you want this too and wondering about the practical details.
This database* is an ongoing project to aggregate tools and resources for artists, engineers, curators & researchers interested in incorporating machine learning (ML) and other forms of artificial intelligence (AI) into their practice. Resources in the database come from our partners and network; tools cover a broad spectrum of possibilities presented by the current advances in ML like enabling users to generate images from their own data, create interactive artworks, draft texts or recognise objects. Most of the tools require some coding skills, however, we’ve noted ones that don’t. Beginners are encouraged to turn to RunwayML or entries tagged as courses.
*This database isn’t comprehensive—it's a growing collection of research commissioned & collected by the Creative AI Lab. The latest tools were selected by Luba Elliott. Check back for new entries.
Via : https://docs.google.com/document/d/1TkusCE5mS4tuTYoBwaTV4aJKdSVsf9jFKsGJCx8M05c/edit
This is a list of smaller tools that might be useful in building your game/website/interactive project. Although I’ve mostly also included ‘standards’, this list has a focus on artful tools & toys that are as fun to use as they are functional.
The goal of this list is to enable making entirely outside of closed production ecosystems or walled software gardens.
Explore the inventions, technology and ideas of science fiction writers
Date Device Name (Novel Author)
1634 Weightlessness (Kepler) (from Somnium (The Dream) by Johannes Kepler)
1638 Weightlessness in Space (from The Man in the Moone by Francis Godwin)
1638 Gansas (from The Man in the Moone by Francis Godwin)
1657 Moon Machine - very early description (from A Voyage to the Moon by Cyrano de Bergerac)
1705 Cogitator (The Chair of Reflection) (from The Consolidator by Daniel Defoe)
1726 Knowledge Engine - machine-made expertise (from Gulliver's Travels by Jonathan Swift)
1726 Geometric Modeling - eighteenth century NURBS (from Gulliver's Travels by Jonathan Swift)
1726 Bio-Energy - produce electricity from organic material (from Gulliver's Travels by Jonathan Swift)
1726 Laputa - a floating island (from Gulliver's Travels by Jonathan Swift)
1727 Androide - the original (from Cyclopaedia by Ephraim Chambers)
The new Collection online
From Dürer to the Rosetta Stone, explore 4.5 million objects.
The database is based on the British Museum's collection management tool, where we record what we know about our collection. It was created for the Museum to store information for its own use, and is therefore full of specialised terms, abbreviations and shorthand.
The Museum has been working on the database for more than 40 years and, even with more than two million records, we've only catalogued about half of the collection. We're adding and improving records every day but, even so, an object record may not have been checked. In many cases, the most recent research has not yet been added. There will be mistakes and omissions, but the Museum chooses to publish the data, rather than hold it until it is 'finished', as there will always be new information about an object. Only personal and sensitive information has been withheld.

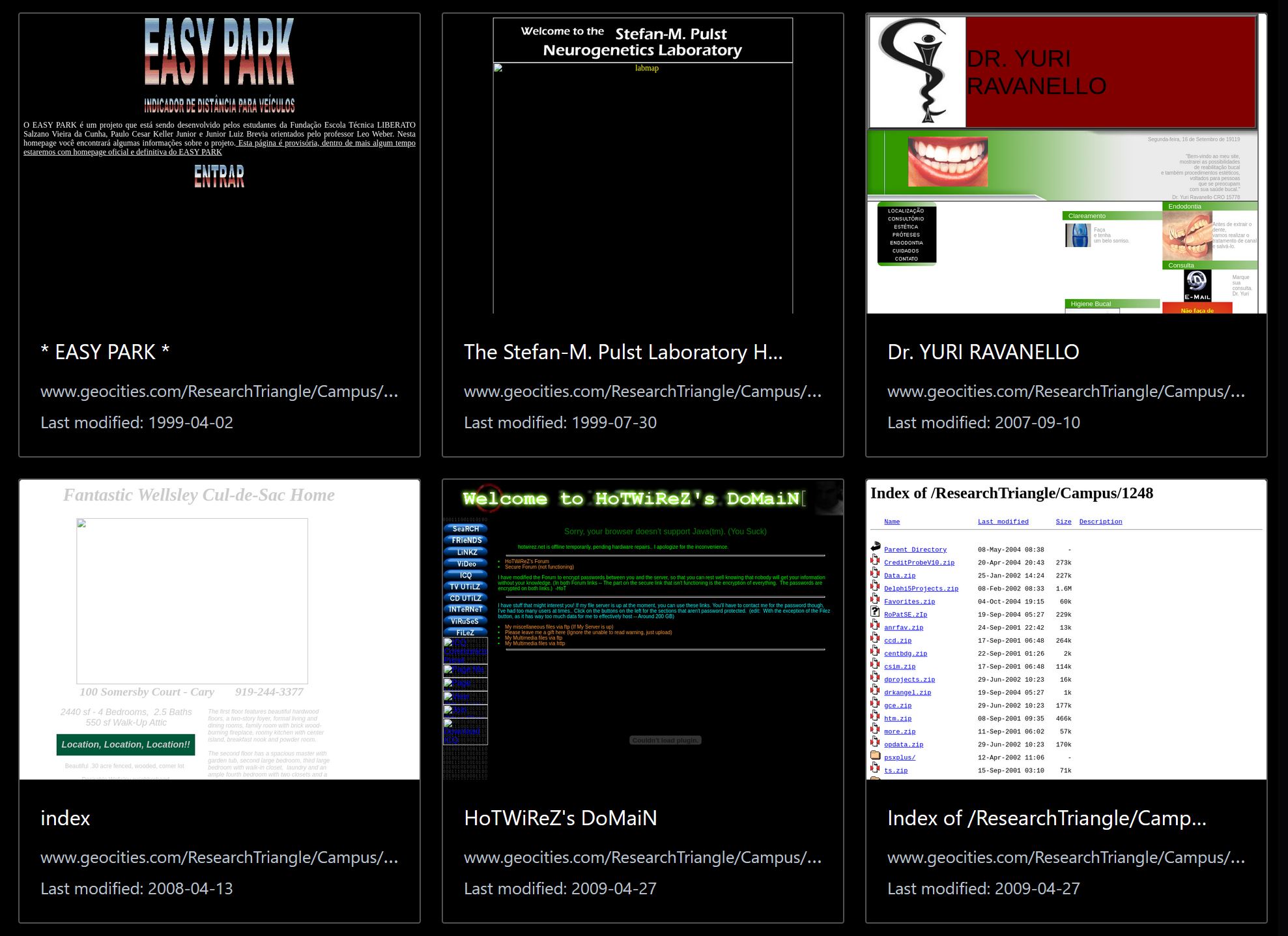
a project to excavate shut down, abandoned web ruins and restore them to surfable, accessible, searchable, remixable condition
somewhere between a library and a living museum, we're working on experimental new ways to close the gap between archival and visibility of the web that was lost
launched
geocities
myspace musicon deck
aol hometown
netscape web sites
geocities japan
FortuneCity
tbaThese 16,000 BBC Sound Effects are made available by the BBC in WAV format to download for use under the terms of the RemArc Licence. The Sound Effects are BBC copyright, but they may be used for personal, educational or research purposes, as detailed in the license.
Writing Machines is a resource dedicated to various projects related to electronic literature/books/writing/art curated by Julia Garcia
The Organization for Transformative Works (OTW) is a nonprofit organization, established by fans in 2007, to serve the interests of fans by providing access to and preserving the history of fanworks and fan culture in its myriad forms. We believe that fanworks are transformative and that transformative works are legitimate.
We are proactive and innovative in protecting and defending our work from commercial exploitation and legal challenge. We preserve our fannish economy, values, and creative expression by protecting and nurturing our fellow fans, our work, our commentary, our history, and our identity while providing the broadest possible access to fannish activity for all fans.




