Our wiki is a comprehensive encyclopedia of online and offline aesthetics! We are a community dedicated to the identification, observation, and documentation of visual schemata.
What is an aesthetic? Why does everyone always argue about what aesthetics should be on this wiki?
The short answer: A collection of visual schema that creates a "mood."
Some types of aesthetics include:
Aesthetics originated from Internet communities (Ex: Cottagecore, Dark Academia)
National cultures (Americana, Traditional Polish) Note: Most articles that try to describe a national culture will be deleted. These articles should have a higher quality and risk stereotyping a nation.
Genres of fiction with established visual tropes (Ex: Cyberpunk, Gothic)
Holidays with iconic imagery and colors (Ex: Christmas, Halloween)
Locations that have expected activities, components, and types of people (Ex: Fanfare, Urbancore)
Music genres with consistent visual motifs present in cover art, music videos, etc (Ex: City Pop, Emo)
This does not mean all music genres should be present. For example, Pop and Alternative bands' do not have shared visual traits.
Periods of history with distinct visuals (Ex: Victorian, Y2K)
Stereotypes (Ex: Brocore, VSCO)
Subcultures that share music genres and fashion styles (Ex: Raver, Skinheads)The long answer:
The word "aesthetic" originated as the philosophical discussion about what beauty is, how we should approach it, and why it exists. However, Millennials and Generation Z started using that term as an adjective that describes what they personally consider beautiful. For example: "After Denise finished watching The Virgin Suicides, she said, 'Wow. That was so aesthetic.'"
Aesthetics have now come to mean a collection of images, colors, objects, music, and writings that creates a specific emotion, purpose, and community. It is largely dependent on personal taste, cultural background, and exposure to different pieces of media. This definition is not official and can be debated. There is currently no dictionary definition that captures the complexity of this phenomenon, which arose in the Internet youth. Rather, people who participate in the community "know it when they see it." These elements are constantly debated, as the opinion on whether or not some aesthetics exist or are valid is constantly debated. This is especially true since everyone's own personal life factors into their opinions.
Here is an example of a debate that is going on within the community. Whether or not Lolita is an aesthetic varies on what counts as visual elements. On one hand, lace, petticoats, and bows are valid elements of visual schema. Those elements combine to spark feelings of kawaii, de-sexualization, rebellion, and appreciation of antique. On the other hand, aesthetics are made up of elements other than fashion, such as home decor or music. Fashion is the visual element, rather than the components making up the coord/outfit. That element is part of broader schemas such as Goth and Victorian. What counts as an element and what qualifies as sparking an emotion is a complicated subject.
So right now, the subject is trying to be defined by the community. What either fits into a larger schema or is distinct enough to warrant its own aesthetic is difficult to say and would depend on who you are asking.
Clip retrieval works by converting the text query to a CLIP embedding , then using that embedding to query a knn index of clip image embedddings
https://github.com/rom1504/clip-retrieval

“Although our study doesn’t present ways to mitigate negative hunger-induced emotions, research suggests that being able to label an emotion can help people to regulate it, such as by recognising that we feel angry simply because we are hungry. Therefore, greater awareness of being ‘hangry’ could reduce the likelihood that hunger results in negative emotions and behaviours in individuals.”



A book of 1000 paintings and illustrations of robots created by artificial intelligence. The author generated all of the images in this book by writing original prompts for DALL·E 2, OpenAI’s AI system that can create realistic images and art from a description in natural language. Upon generating the images, the author curated and arranged the images to their own liking and takes ultimate responsibility for the content of this publication.
https://openai.com/dall-e-2/
https://github.com/CompVis/latent-diffusion
https://huggingface.co/spaces/multimodalart/latentdiffusion
https://mirror.xyz/0x0f6712c6ac4f02f47cA8b5cf200B224aE6fD8B69/AYLAsdtM090nHWpvWQ13exkaJoNyllkhxa9ffEUPOrg
Bitmap Image to 'Pixel Perfect' Vector Graphic or 3D model
The HTML5 application on this page converts your bitmap image online into a Scalable Vector Graphics or 3D model.
The result is 'pixel perfect'/lossless.
Rutt-Etra-Izer is a WebGL emulation of the classic Rutt-Etra video synthesizer. This demo replicates the Z-displacement, scanned-line look of the original, but does not attempt to replicate it’s full feature set.

The demo allows you to drag and drop your own images, manipulate them and save the output. Images are generated by scanning the pixels of the input image from top to bottom, with scan-line separated by the ‘Line Separation’ amount. For each line generated, the z-position of the vertices is dependent on the brightness of the pixels.
20 alternative interfaces for creating and editing images and text
https://github.com/constraint-systems
Flow
An experimental image editor that lets you set and direct pixel-flows.
Fracture
Shatter and recombine images using a grid of viewports.
Tri
Tri is an experimental image distorter. You can choose an image to render using a WebGL quad, adjust the texture and position coordinates to create different distortions, and save the result.
Tile
Layout images using a tiling tree layout. Move, split, and resize images using keyboard controls.
Sift
Slice an image into multiple layers. You can offset the slices to create interference patterns and pseudo-3D effects.
Automadraw
Draw and evolve your drawing using cellular automata on a pixel grid with two keyboard-controlled cursors.
Span
Lay out and rearrange text, line by line, using keyboard controls.
Stamp
Image-paint from a source image palette using keyboard controls.
Collapse
Collapse an image into itself using ranked superpixels.
Res
Selectively pixelate an image using a compression algorithm.
Rgb
Pixel-paint using keyboard controls.
Face
Edit both the text and the font it is rendered in.
Pal
Apply an eight-color terminal color scheme to an image. Use the keyboard controls to choose a theme, set thresholds, and cycle hues.
Bix
Draw on binary to glitch text.
Diptych
Pixel-reflow an image to match the dimensions of your text. Save the result as a diptych.
Slide
Divide and slide-stretch an image using keyboard controls.
Freeconfig
Push around image pixels in blocks.
Moire
Generate angular skyscapes using Asteroids-like ship controls.
Hex
A keyboard-driven, grid-based drawing tool.
Etch
A keyboard-based pixel drawing tool.
About
Constraint Systems is a collection of experimental web-based creative tools. They are an ongoing attempt to explore alternative ways of interacting with pixels and text on a computer screen. I hope to someday build these ideas into something larger, but the plan for now is to keep the scopes small and the releases quick.
Can I use the art I find here? How should I credit the artist?
Yes, you can use any of the art submitted to this site. Even in commercial projects. Just be sure to adhere to the license terms. Artists often indicate how they would like to be credited in the "Copyright/Attribution Notice:" section of the submission. You can find this between the submission's description and the list of downloadable files. If no Copyright/Attribution Notice instructions are given, a good way to credit an author for any asset is to put the following text in your game's credits file and on your game's credits screen:
"[asset name]" by [author name] licensed [license(s)]: [asset url]For example:
"Whispers of Avalon: Grassland Tileset" by Leonard Pabin licensed CC-BY 3.0, GPL 2.0, or GPL 3.0: https://opengameart.org/node/3009OpenGameArt Search + Reverse Image Search
Hint: Start search term with http(s):// for reverse image search.
🌑😄🌑🌑🌑🌑🌑🌑🌑🌑
🌑🌑🌑🌑🌑🌑🌑🌑🌑🌑
🌑🌑🌑🌓🌗🌓🌗🌑😄🌑
🌑🌑🌑🌓🌗🌓🌗🌑🌑🌑
🌑🌑🌑🌓🌕🌕🌗🌑🌑🌑
🌑😄🌑🌓🌗🌓🌗🌑🌑🌑
🌑🌑🌑🌓🌗🌓🌗🌑🌑🌑
🌑🌑🌑🌑🌑🌑🌑🌑🌑🌑
🌑🌑🌑🌑🌓🌗🌑🌑🌑🌑
🌑🌑🌑🌑🌓🌗🌑🌑😄🌑
🌑🌑🌑🌑🌓🌗🌑🌑🌑🌑
🌑😄🌑🌑🌓🌗🌑🌑🌑🌑
🌑🌑🌑🌑🌓🌗🌑🌑🌑🌑
🌑🌑🌑🌑🌑🌑🌑🌑🌑🌑

Neural Cellular Automata (NCA We use NCA to refer to both Neural Cellular Automata and Neural Cellular Automaton.) are capable of learning a diverse set of behaviours: from generating stable, regenerating, static images , to segmenting images , to learning to “self-classify” shapes . The inductive bias imposed by using cellular automata is powerful. A system of individual agents running the same learned local rule can solve surprisingly complex tasks. Moreover, individual agents, or cells, can learn to coordinate their behavior even when separated by large distances. By construction, they solve these tasks in a massively parallel and inherently degenerate Degenerate in this case refers to the biological concept of degeneracy. way. Each cell must be able to take on the role of any other cell - as a result they tend to generalize well to unseen situations.
In this work, we apply NCA to the task of texture synthesis. This task involves reproducing the general appearance of a texture template, as opposed to making pixel-perfect copies. We are going to focus on texture losses that allow for a degree of ambiguity. After training NCA models to reproduce textures, we subsequently investigate their learned behaviors and observe a few surprising effects. Starting from these investigations, we make the case that the cells learn distributed, local, algorithms.
To do this, we apply an old trick: we employ neural cellular automata as a differentiable image parameterization .
Welcome to Smithsonian Open Access, where you can download, share, and reuse millions of the Smithsonian’s images—right now, without asking. With new platforms and tools, you have easier access to more than 3 million 2D and 3D digital items from our collections—with many more to come. This includes images and data from across the Smithsonian’s 19 museums, nine research centers, libraries, archives, and the National Zoo.
What will you create?
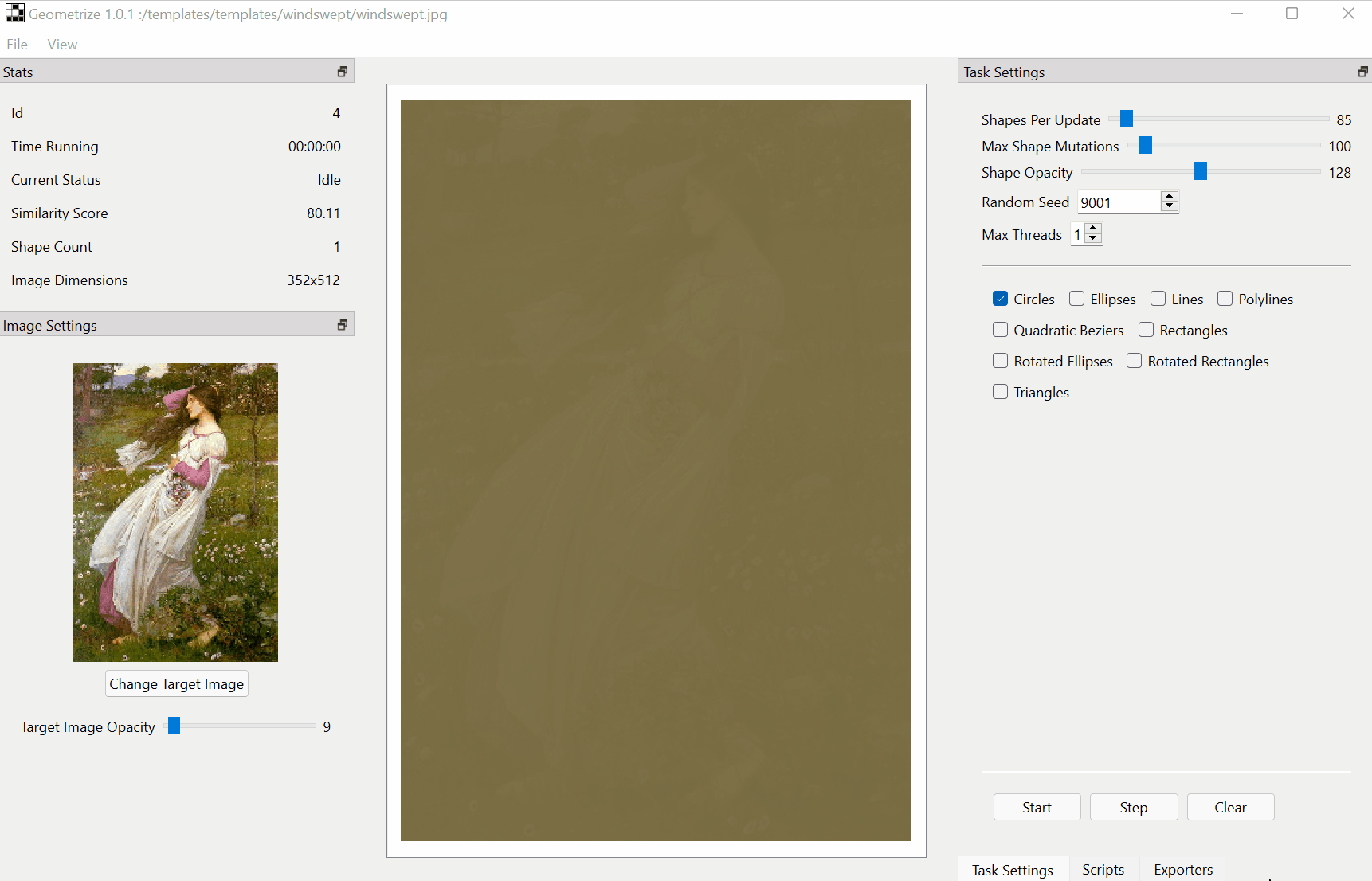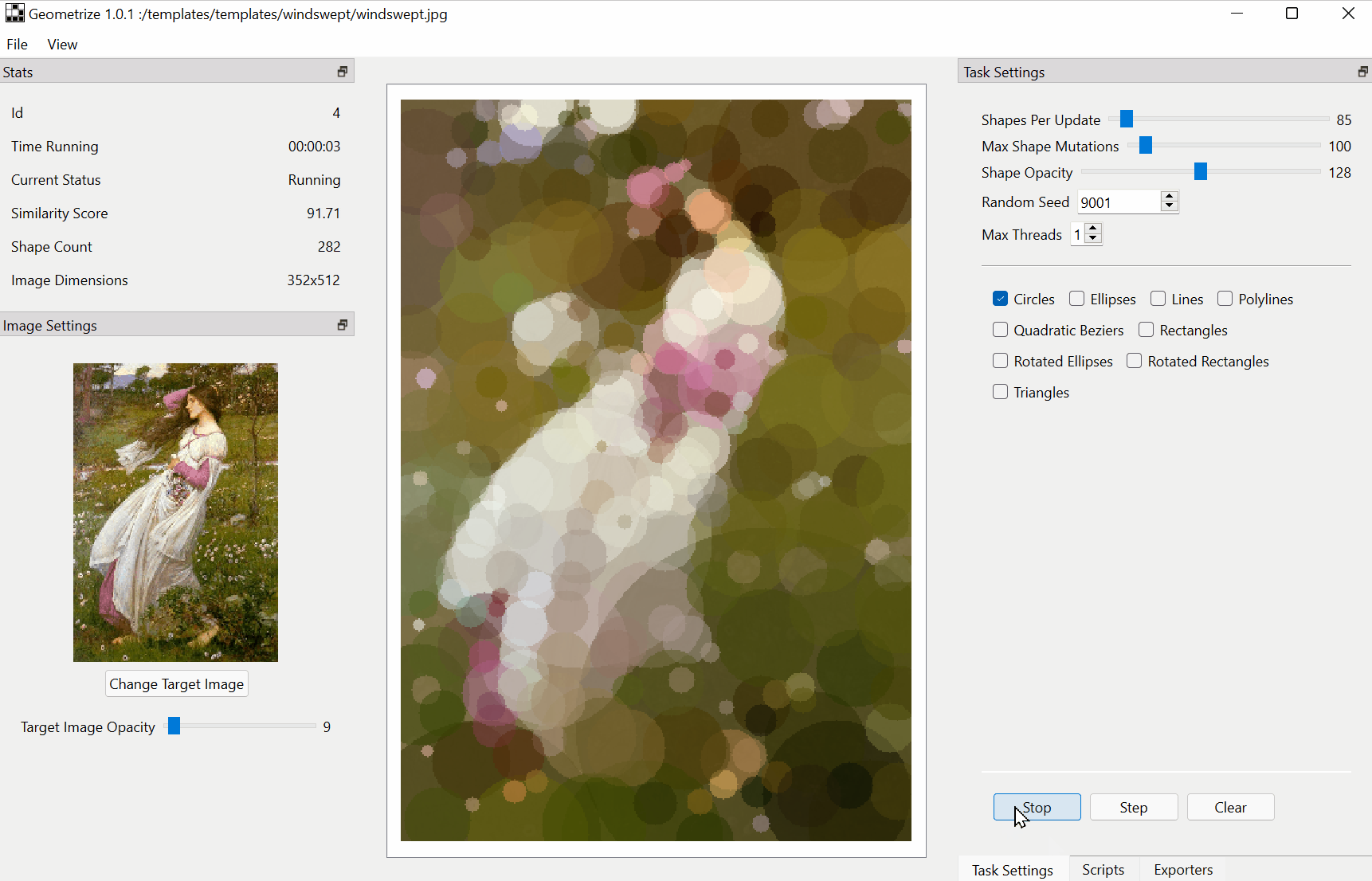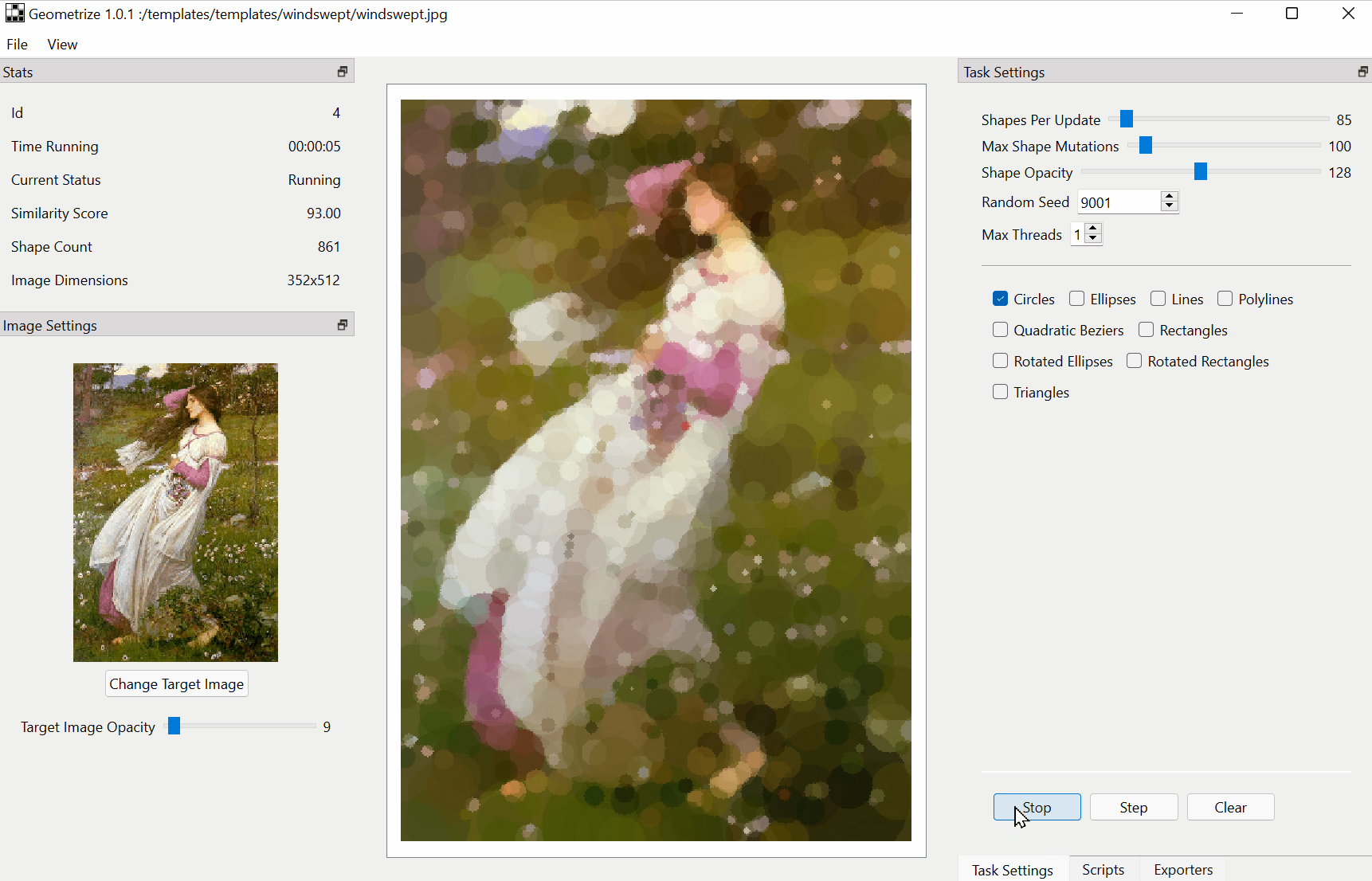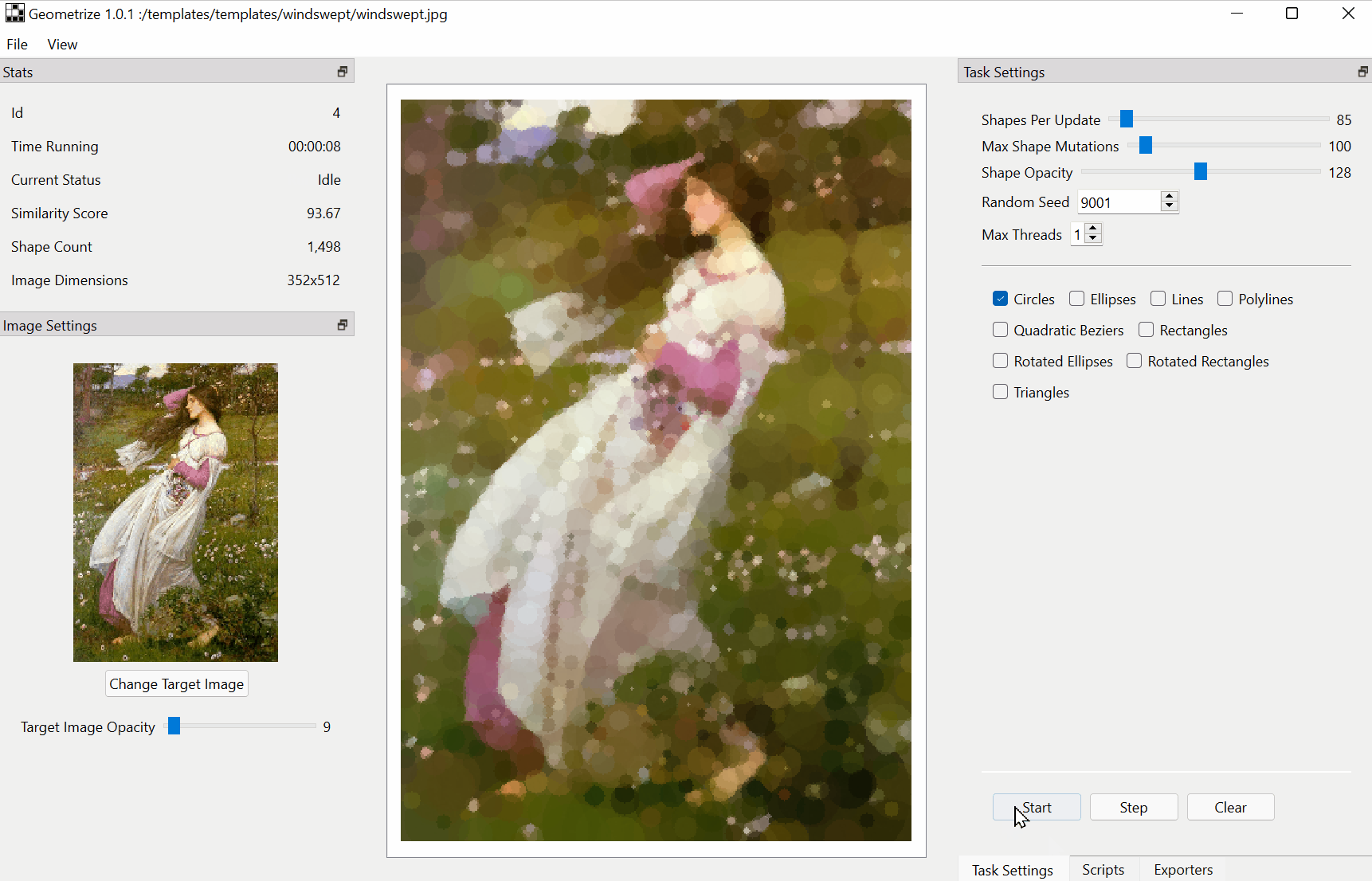
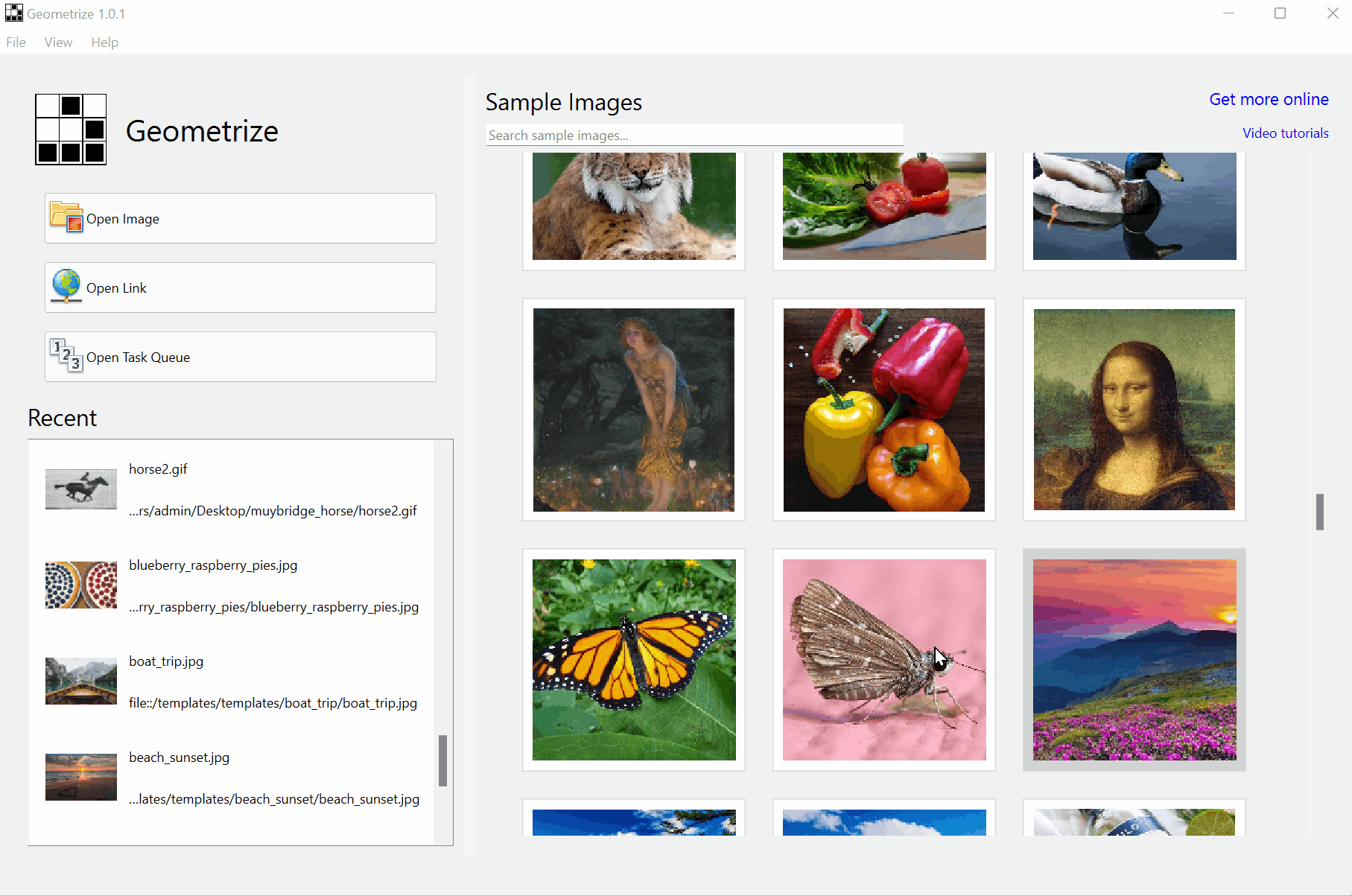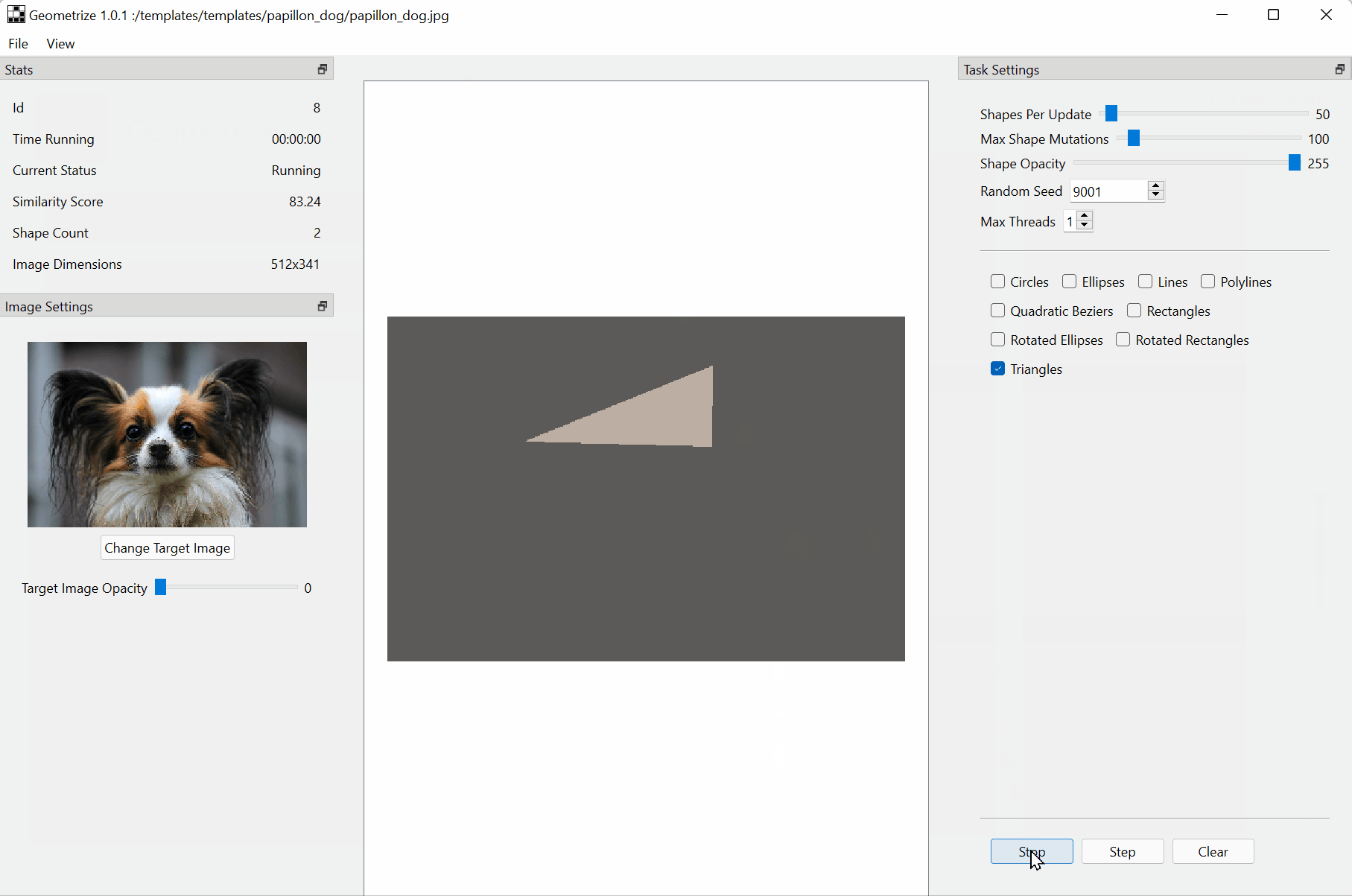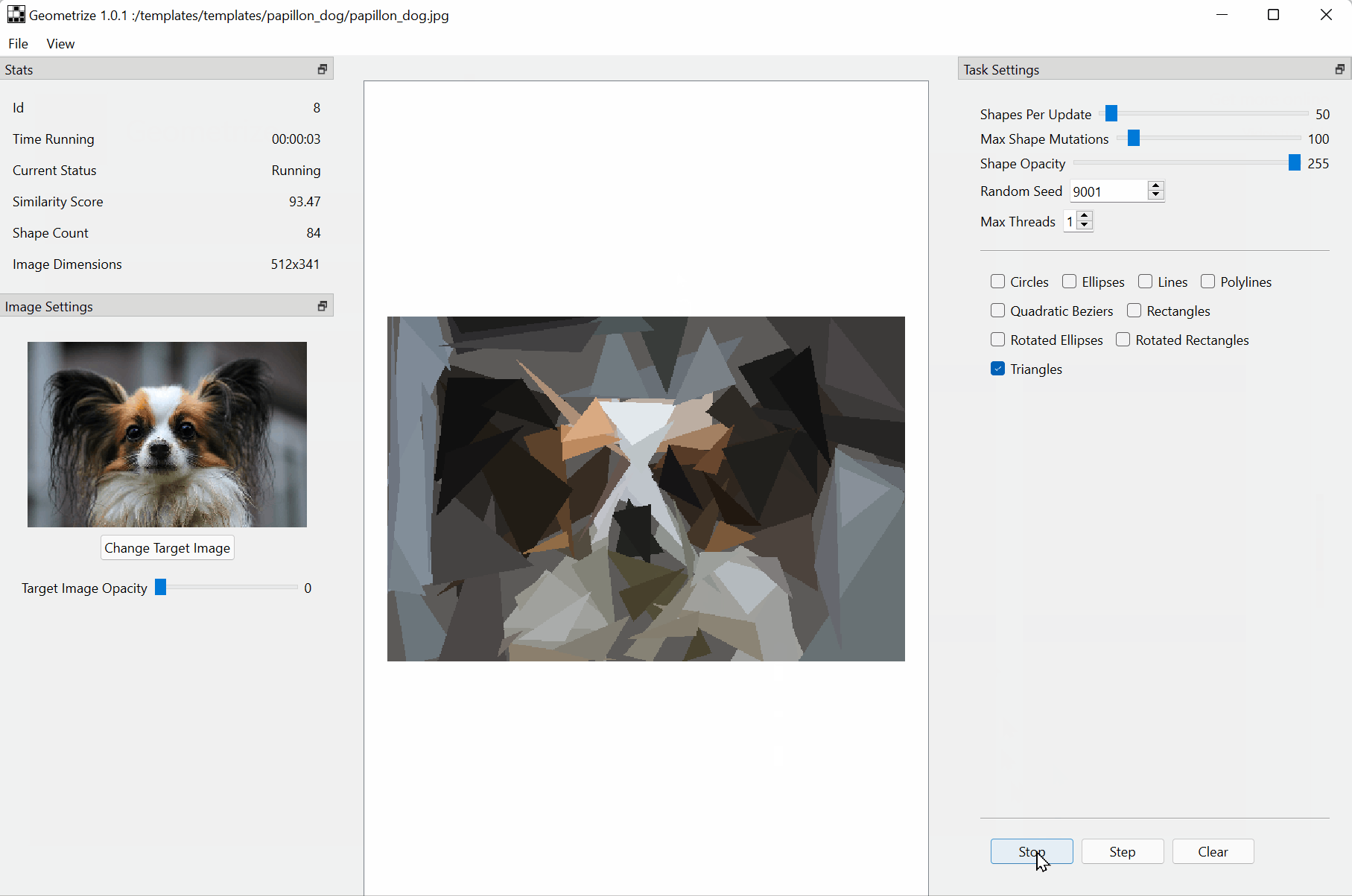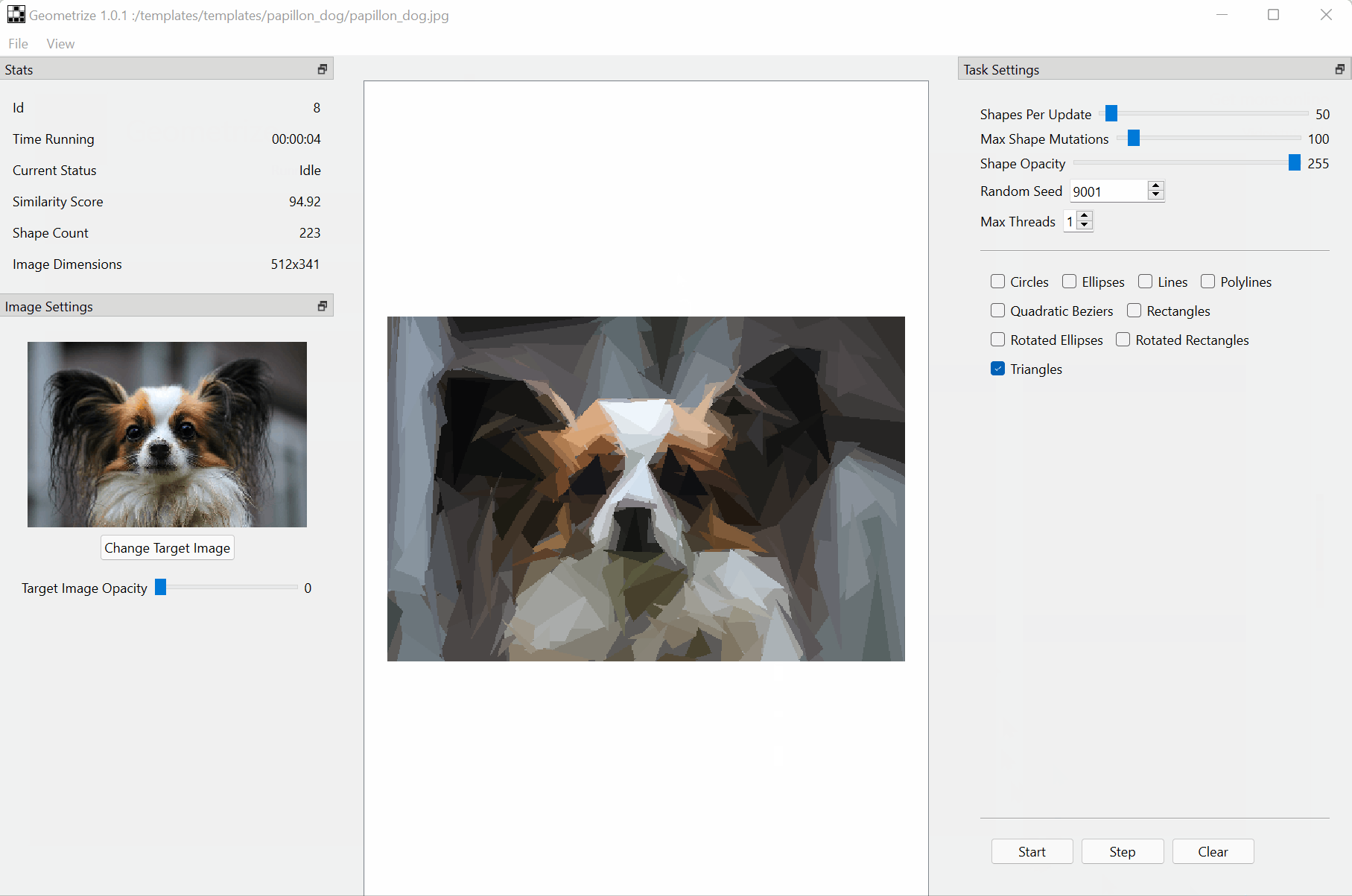
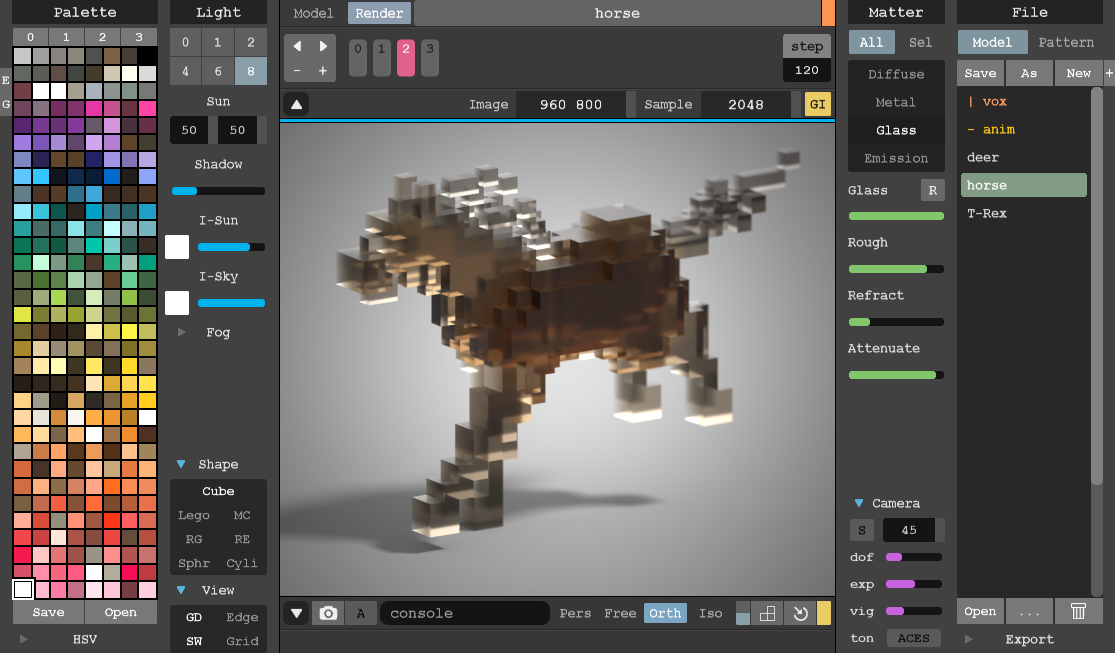
Download :https://github.com/Tw1ddle/geometrize/releases
Features
Recreate images as geometric primitives.
Start with hundreds of images with preset settings.
Export geometrized images to SVG, PNG, JPG, GIF and more.
Export geometrized images as HTML5 canvas or WebGL webpages.
Export shape data as JSON for use in custom projects and creations.
Control the algorithm at the core of Geometrize with ChaiScript scripts.The papers summarized here are mainly from 2017 onwards.
Please refer to the Survey paper(Image Aesthetic Assessment:An Experimental Survey) before 2016.
Optical illusions don’t “trick the eye” nor “fool the brain”, nor reveal that “our brain sucks”, … but are fascinating!
They also teach us about our visual perception, and its limitations. My selection emphazises beauty and interactive experiments; I also attempt explanations of the underlying visual mechanisms where possible.
Returning visitor? Check →here for History/News
»Optical illusion« sounds derogative, as if exposing a malfunction of the visual system. Rather, I view these phenomena as highlighting particular good adaptations of our visual system to its experience with standard viewing situations. These experiences are based on normal visual conditions, and thus under unusual contexts can lead to inappropriate interpretations of a visual scene (=“Bayesian interpretation of perception”).
If you are not a vision scientist, you might find my explanations too highbrow. That is not on purpose, but vision research simply is not trivial, like any science. So, if an explanation seems gibberish, simply enjoy the phenomenon 😉.
A showcase with creative machine learning experiments










Web scraping describes techniques for automatically downloading and processing web content, or converting online text and other media into structured data that can then be used for various purposes. In short, the user writes a program to browse and analyze the web on their behalf, rather than doing so manually. This is a common practice in silicon valley, where open html pages are transformed into private property: Facebook began as a (horny) web scraping project, as did Google and all other search engines. Web scraping is also frequently used to acquire the massive datasets needed to train machine learning models, and has become an important research tool in fields such as journalism and sociology.
I define "scrapism" as the practice of web scraping for artistic, emotional, and critical ends. It combines aspects of data journalism, conceptual art, and hoarding, and offers a methodology to make sense of a world in which everything we do is mediated by internet companies. These companies surveill us, vacuum up every trace we leave behind, exploit our experiences and interject themselves into every possible moment. But in turn they also leave their own traces online, traces which when collected, filtered, and sorted can reveal (and possibly even alter) power relations. The premise of scrapism is that everything we need to know about power is online, hiding in plain sight.
This is a work-in-progress guide to web scraping as an artistic and critical practice, created by Sam Lavigne. I will be updating it over the coming months! I'll also be doing occasional live demos either on Twitch or YoutTube.

Shrub is a tool for painting-and-traveling, and even for painting while moving your own body (for example to use the color of your own pants).
If you touch with two fingers, you can immediately send your drawing as an SMS message. Shrub is designed as a mobile communication tool as much as a mobile drawing tool.
More pro tips: For the best drawings, pinch with your fingers to change the brush size. Twist with your fingers to change the brush softness. And of course, tap with one finger to show and hide the viewfinder.
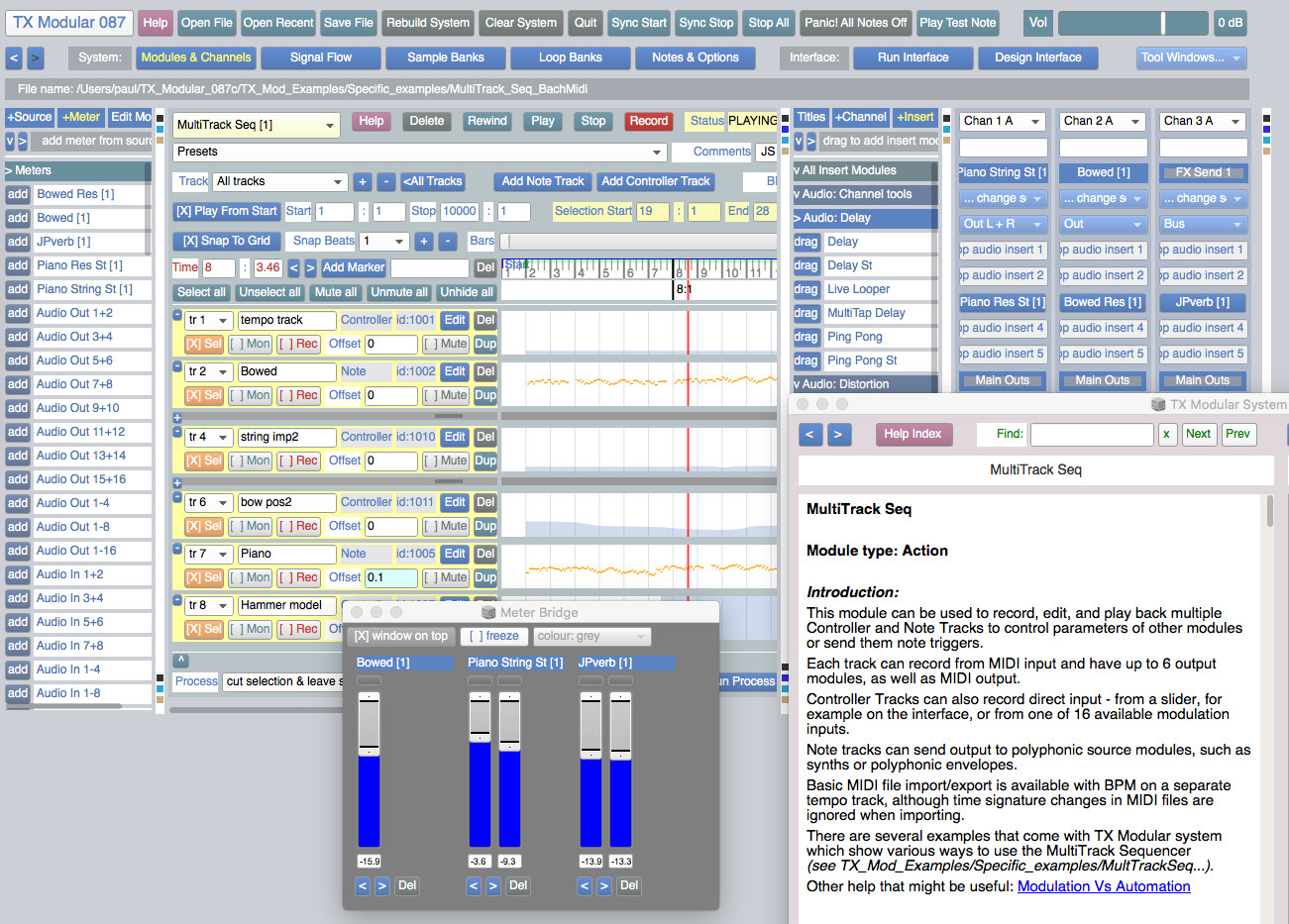
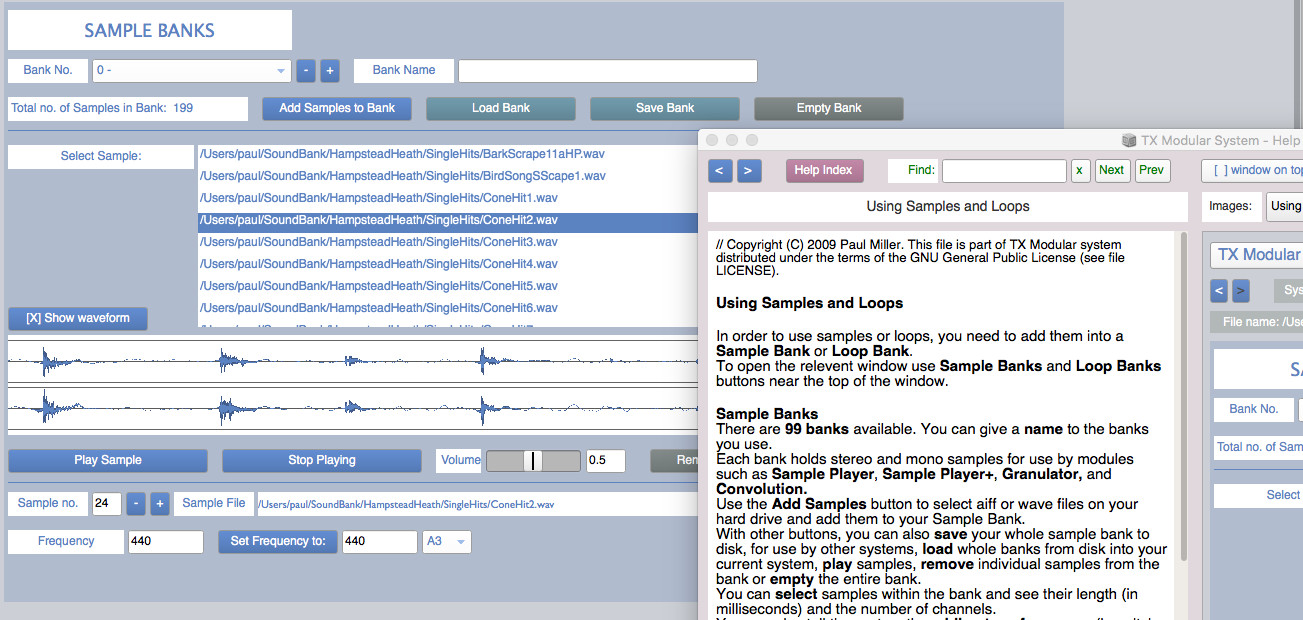
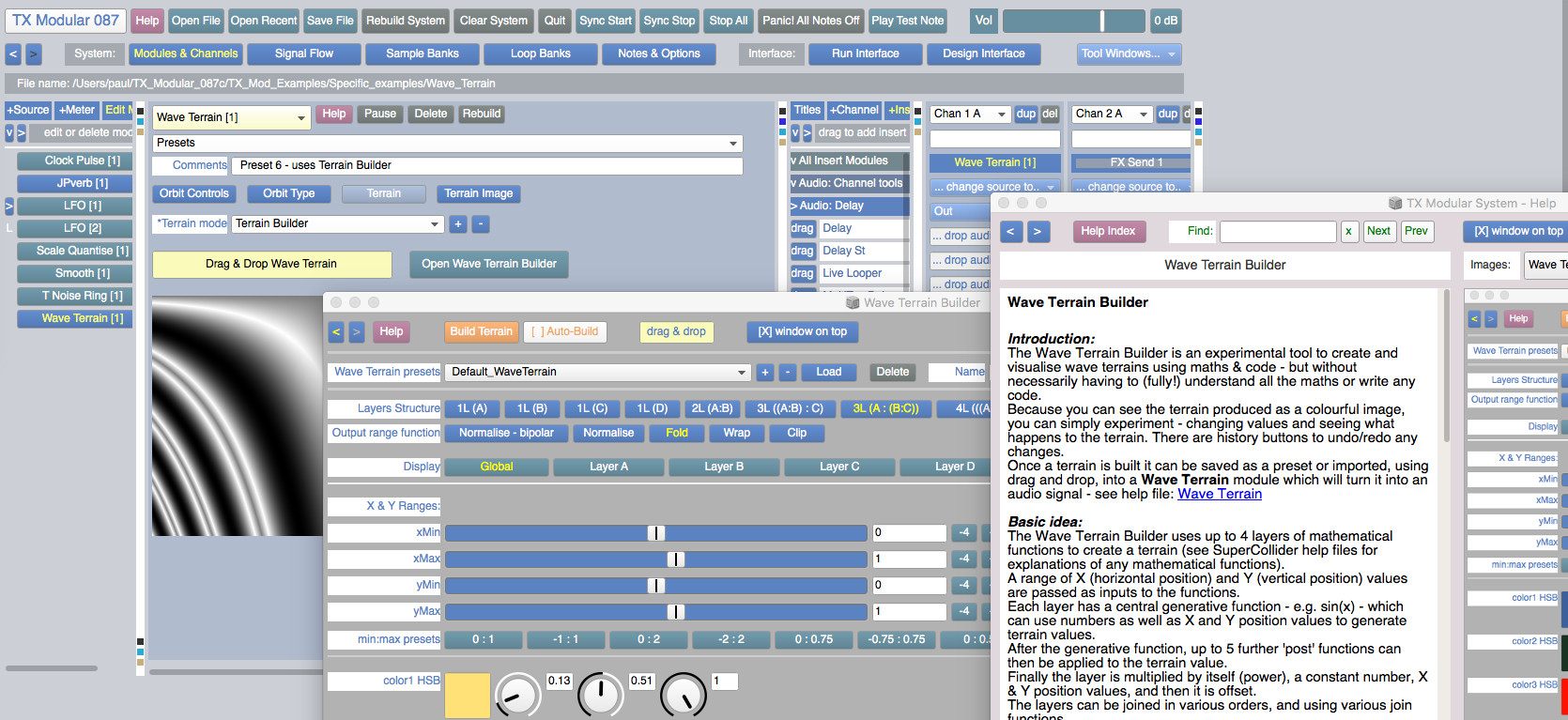
The TX Modular System is open source audio-visual software for modular synthesis and video generation, built with SuperCollider (https://supercollider.github.io) and openFrameworks (https://openFrameworks.cc).
It can be used to build interactive audio-visual systems such as: digital musical instruments, interactive generative compositions with real-time visuals, sound design tools, & live audio-visual processing tools.
This version has been tested on MacOS (0.10.11) and Windows (10). The audio engine should also work on Linux.
The visual engine, TXV, has only been built so far for MacOS and Windows - it is untested on Linux.
The current TXV MacOS build will only work with Mojave (10.14) or earlier (10.11, 10.12 & 10.13) - but NOT Catalina (10.15) or later.
You don't need to know how to program to use this system. But if you can program in SuperCollider, some modules allow you to edit the SuperCollider code inside - to generate or process audio, add modulation, create animations, or run SuperCollider Patterns.
The new Collection online
From Dürer to the Rosetta Stone, explore 4.5 million objects.
The database is based on the British Museum's collection management tool, where we record what we know about our collection. It was created for the Museum to store information for its own use, and is therefore full of specialised terms, abbreviations and shorthand.
The Museum has been working on the database for more than 40 years and, even with more than two million records, we've only catalogued about half of the collection. We're adding and improving records every day but, even so, an object record may not have been checked. In many cases, the most recent research has not yet been added. There will be mistakes and omissions, but the Museum chooses to publish the data, rather than hold it until it is 'finished', as there will always be new information about an object. Only personal and sensitive information has been withheld.

No Home Like Place Airbnb is a global hotel filled with the same recurring items. Bed, chair, potted plant, all catered to our cosmopolitan sensibilities. We end up in a place that's completely interchangeable; a room is a room is a room. An algorithm finds these recurring items and replaces them with the same items from other listings.
ComboGAN: Unrestrained Scalability for Image Domain Translation Asha Anoosheh, Eirikur Augustsson, Radu Timofte, Luc van Gool In Arxiv, 2017.
https://arxiv.org/pdf/1712.06909.pdf
This year alone has seen unprecedented leaps in the area of learning-based image translation, namely CycleGAN, by Zhuet al. But experiments so far have been tailored to merely two domains at a time, and scaling them to more would re-quire an quadratic number of models to be trained. And with two-domain models taking days to train on current hardware,the number of domains quickly becomes limited by the time and resources required to process them. In this paper, we pro-pose a multi-component image translation model and training scheme which scales linearly - both in resource consumption and time required - with the number of domains. We demonstrate its capabilities on a dataset of paintings by 14different artists and on images of the four different seasons in the Alps. Note that 14 data groups would need(14choose2) =91 different CycleGAN models: a total of 182 genera-tor/discriminator pairs; whereas our model requires only 14generator/discriminator pairs

UNIT: UNsupervised Image-to-image Translation Networks : https://github.com/mingyuliutw/UNIT
![]()
Utility library to easily connect to RunwayML from Processing
Feel free to replace this paragraph with a description of the Library.
Contributed Libraries are developed, documented, and maintained by members of the Processing community. Further directions are included with each Library. For feedback and support, please post to the Discourse. We strongly encourage all Libraries to be open source, but not all of them are.
https://github.com/runwayml/processing-library


![]()

Installation
Download https://github.com/runwayml/processing-library/releases/download/latest/RunwayML.zip
Unzip into Documents > Processing > libraries
Restart Processing (if it was already running)
Create beautiful, wild and weird images with GAN.

A light Rust API for Multiresolution Stochastic Texture Synthesis [1], a non-parametric example-based algorithm for image generation.
![]()
Pixel-art scaling algorithms are graphical filters that are often used in video game emulators to enhance hand-drawn 2D pixel art graphics. The re-scaling of pixel art is a specialist sub-field of image rescaling.
As pixel-art graphics are usually in very low resolutions, they rely on careful placing of individual pixels, often with a limited palette of colors. This results in graphics that rely on a high amount of stylized visual cues to define complex shapes with very little resolution, down to individual pixels. This makes image scaling of pixel art a particularly difficult problem.
A number of specialized algorithms[1] have been developed to handle pixel-art graphics, as the traditional scaling algorithms do not take such perceptual cues into account.
Since a typical application of this technology is improving the appearance of fourth-generation and earlier video games on arcade and console emulators, many are designed to run in real time for sufficiently small input images at 60 frames per second. This places constraints on the type of programming techniques that can be used for this sort of real-time processing. Many work only on specific scale factors: 2× is the most common, with 3×, 4×, 5× and 6× also present.
Plugin for GIMP : https://github.com/bbbbbr/gimp-plugin-pixel-art-scalers
Waifu2x
https://en.wikipedia.org/wiki/Waifu2x
https://github.com/lltcggie/waifu2x-caffe/releases
https://github.com/imPRAGMA/W2XKit
https://old.reddit.com/r/WaifuUpscales/new/
https://github.com/BlueCocoa/waifu2x-ncnn-vulkan-macos/releases
https://old.reddit.com/r/Dandere2x/
https://old.reddit.com/r/waifu2x
https://github.com/AaronFeng753/Waifu2x-Extension
https://github.com/K4YT3X/video2x
https://old.reddit.com/r/AnimeResearch
Quote from a reddit comment :
A short list, ordered after output quality and setup time:
SRGAN, Super-resolution generative adversarial network : https://github.com/topics/srgan,
Other implementations: https://github.com/tensorlayer/srgan
https://github.com/brade31919/SRGAN-tensorflow
https://github.com/titu1994/Super-Resolution-using-Generative-Adversarial-Networks
Neural Enhance: https://github.com/alexjc/neural-enhance/
Photoshop: The newest PS version (19.x, since October 2017 release) also has a new upscaling method, called "Preserve Details 2.0 Upscale" but compared to SRGAN the results clearly lack sharp and fine details. You have asked for an App and PS is easy to use and can be automated.
Overview of the most popular algorithms:
https://github.com/IvoryCandy/super-resolution
(VDSR, EDSR, DCRN, SubPixelCNN, SRCNN, FSRCNN, SRGAN)
Not in the list above:
LapSRN: https://github.com/phoenix104104/LapSRN
SelfExSR: https://github.com/jbhuang0604/SelfExSR
RAISR, developed by Google:
https://github.com/MKFMIKU/RAISR
https://github.com/movehand/raisr
Despite the rise of ebooks, the interest in cover design and the look of physical books is probably stronger than ever. The rate of books being published grows ever higher, and they all need covers, even if it's just a thumbnail for a Kindle edition on Amazon.
Cover designers the world over have access, via online art databases and stock libraries, to a vast array of images that can be used to decorate and, with any luck, sell books. Unfortunately, all those designers tend to have access to the same databases and libraries, which means you sometimes end up with books which feature photographs that look strangely familiar…
Declassifier
Custom Software, COCO Dataset (corrected). 2 days 5 hours 25 min. 2019
Declassifier processes pictures using the YOLO computer vision algorithm. Instead of showing the program's prediction, the picture is overlayed with images from COCO, the training dataset from which the algorithm learned in the first place.
The data by which machine learning algorithms learn to make predictions is hardly ever shown, let alone credited. By doing both, Declassifier exposes the myth of magically intelligent machines, instead applauding the photographers who made the technical achievement possible. In fact, when showing the actual training pictures, credit is not only due but mandatory.

The tl;dr
We should all be automating our image compression.
Image optimization should be automated. It’s easy to forget, best practices change, and content that doesn’t go through a build pipeline can easily slip. To automate: Use imagemin or libvips for your build process. Many alternatives exist.
Most CDNs (e.g. Akamai) and third-party solutions like Cloudinary, imgix, Fastly’s Image Optimizer, Instart Logic’s SmartVision or ImageOptim API offer comprehensive automated image optimization solutions.
The amount of time you’ll spend reading blog posts and tweaking your configuration is greater than the monthly fee for a service (Cloudinary has a free tier). If you don’t want to outsource this work for cost or latency concerns, the open-source options above are solid. Projects like Imageflow or Thumbor enable self-hosted alternatives.

https://ganbreeder.app/i?k=1f98015a7ce950101ec1c5ee
Ganbreeder is a collaborative art tool for discovering images. Images are 'bred' by having children, mixing with other images and being shared via their URL. This is an experiment in using breeding + sharing as methods of exploring high complexity spaces. GAN's are simply the engine enabling this. Ganbreeder is very similar to, and named after, Picbreeder. It is also inspired by an earlier project of mine Facebook Graffiti which demonstrated the creative capacity of crowds. Ganbreeder uses these BigGAN models and the source code is available.
We call them "seeds". Each seed is a machine learning example you can start playing with. Explore, learn and grow them into whatever you like.



It's all a game of construction — some with a brush, some with a shovel, some choose a pen.
Jackson Pollock

…and some, including myself, choose neural networks. I’m an artist, and I've also been building commercial software for a long while. But art and software used to be two parallel tracks in my life; save for the occasional foray into generative art with Processing and computational photography, all my art was analog… until I discovered GANs (Generative Adversarial Networks).
Since the invention of GANs in 2014, the machine learning community has produced a number of deep, technical pieces about the technique (such as this one). This is not one of those pieces. Instead, I want to share in broad strokes some reasons why GANs are excellent artistic tools and the methods I have developed for creating my GAN-augmented art.
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/
https://github.com/eriklindernoren/PyTorch-GAN
https://heartbeat.fritz.ai/introduction-to-generative-adversarial-networks-gans-35ef44f21193
https://github.com/nightrome/really-awesome-gan
https://github.com/zhangqianhui/AdversarialNetsPapers
https://github.com/io99/Resources
https://github.com/yunjey/pytorch-tutorial
https://github.com/bharathgs/Awesome-pytorch-list
https://old.reddit.com/r/MachineLearning
http://www.codingwoman.com/generative-adversarial-networks-entertaining-intro/
https://medium.com/@jonathan_hui/gan-gan-series-2d279f906e7b
https://www.youtube.com/channel/UC9OeZkIwhzfv-_Cb7fCikLQ/videos
https://www.youtube.com/watch?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&v=aircAruvnKk
https://www.youtube.com/watch?list=PLxt59R_fWVzT9bDxA76AHm3ig0Gg9S3So&v=ZzWaow1Rvho
Repaint your picture in the style of your favorite artist.


About
Our mission is to provide a novel artistic painting tool that allows everyone to create and share artistic pictures with just a few clicks. All you need to do is upload a photo and choose your favorite style. Our servers will then render your artwork for you. We apply an algorithm developed by Leon Gatys, Alexander Ecker and Matthias Bethge. The website was originally created by Łukasz Kidziński and Michał Warchoł. We have now joined forces to provide you with the latest technology in even more accessible way.
Our Team
Five researchers from the Bethge lab at University of Tübingen (Germany), CHILI Lab at École polytechnique fédérale de Lausanne (Switzerland) and Université catholique de Louvain (Belgium).
The Aziz! Light Crew Freeliner is a live geometric animation software built with Processing. The documentation is a little sparse and the ux is rough but powerfull.
Also known as a!LcFreeliner. This software is feature-full geometric animation software built for live projection mapping. Development started in fall 2013.
It is made with Processing. It is licensed as GNU Lesser General Public License. A official release will occur once I have solidified the new architecture developed during this semester.
Using a computer mouse cursor the user can create geometric forms composed of line segments. These can be created in groups, also known as segmentGroup. To facilitate this task the software has features such as centering, snapping, nudging, fixed length segments, fixed angles, grids, and mouse sensitivity adjustment.
This project will fund the production, via crowd sourcing, of a never-before-released translation of Herman Melville's classic Moby Dick in Japanese emoji icons.
Methodology
Each of Moby Dick's 6,438 sentences will be translated 3 times by different Amazon Mechanical Turk workers. Those results will then be voted on by another set of workers, and the most popular version of each sentence will be selected for inclusion in the book.

Here is a sample of a test run I've done on the first couple of chapters:
In the book, the sentences will be arranged with the Emoji on top of the page and the English sentence at the bottom.

Wildfire is a free and user-friendly image-processing software, mostly known for its sophisticated flame-fractal-generator. It is Java-based, open-source and runs on any major computer-plattform. There is also a special Android-version for mobile devices.

An extensive and extendable painting application with an extensive range of features, including: both bitmap and vector graphics; multiple layers; five kinds of color picker; patterns, textures, and gradients; dashed lines and arrowheads; a spirograph generator; and even a cellular automaton tool (pictured below).
Gifski converts video frames to GIF animations using pngquant's fancy features for efficient cross-frame palettes and temporal dithering. It produces animated GIFs that use thousands of colors per frame.
Release : https://github.com/ImageOptim/gifski/releases
Usage
I haven't finished implementing proper video import yet, so for now you need ffmpeg to convert video to PNG frames first:
ffmpeg -i video.mp4 frame%04d.png
and then make the GIF from the frames:
gifski -o file.gif frame*.png
See gifski -h for more options. The conversion might be a bit slow, because it takes a lot of effort to nicely massage these pixels. Also, you should suffer waiting like the poor users who will be downloading these huge files.